
Le RAID 10 reste une référence fréquente dans les infrastructures où le stockage doit absorber des charges soutenues sans provoquer de dérive de latence ni de baisse brutale de performance. Dans les environnements de bases de données, de virtualisation et de services applicatifs critiques, le choix d’un niveau de RAID ne peut pas être réduit à une simple logique de capacité utile. Il faut aussi mesurer la capacité du système à maintenir des IOPS stables, à limiter la pénalité en écriture, à supporter les accès aléatoires simultanés et à réduire l’exposition au risque lors d’une panne disque. C’est sur ce terrain que le RAID 10 conserve un positionnement technique distinct.
Son architecture associe mirroring et striping afin de combiner duplication des données et répartition des accès sur plusieurs disques. Cette structure lui permet d’offrir de très bonnes performances sur les charges transactionnelles, en particulier lorsque les écritures sont fréquentes et que la régularité des temps de réponse compte davantage que l’optimisation maximale de l’espace brut. Contrairement aux niveaux de RAID avec parité, le RAID 10 évite les surcoûts de calcul qui dégradent souvent les performances dans les environnements fortement sollicités. Il est donc régulièrement retenu pour les datastores de machines virtuelles, les journaux transactionnels, les bases SQL et les applications métiers sensibles à la latence.
Cet article examine le RAID 10 sous un angle strictement technique : performances en lecture et en écriture, comportement réel sous charge, niveau de résilience face aux pannes, coût utile par téraoctet et comparaison avec le RAID 5 et le RAID 6. L’objectif est de déterminer dans quels cas le RAID 10 constitue un choix cohérent pour une infrastructure B2B, et dans quels scénarios son surcoût capacitif ne se justifie pas face à des besoins davantage orientés vers la densité de stockage que vers la performance immédiate.
Pourquoi le RAID 10 est-il souvent choisi pour les bases de données et la virtualisation ?
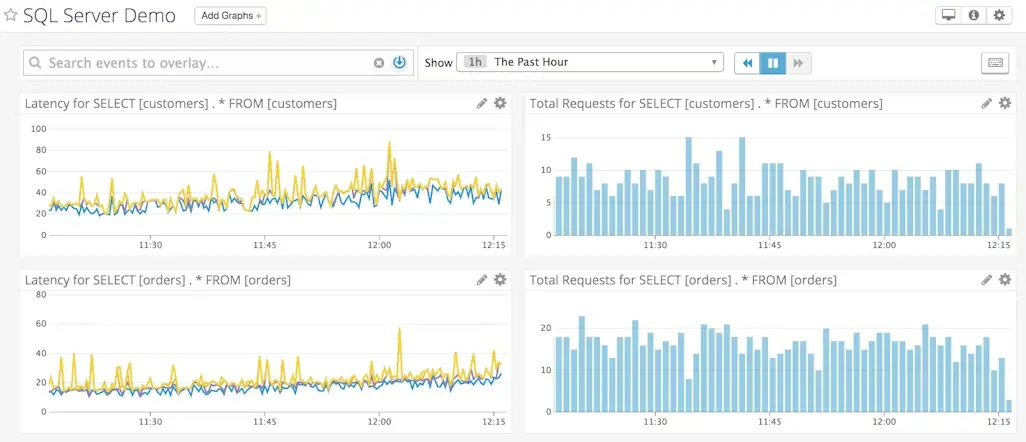
Le RAID 10 occupe une place particulière dans les architectures de stockage professionnelles parce qu’il répond à deux contraintes qui coexistent dans les bases de données et la virtualisation : maintenir un niveau de performances stable sous charge et limiter le risque opérationnel en cas de défaillance de disques. Dans ces environnements, le stockage n’est pas seulement évalué sur un débit séquentiel théorique. Il est jugé sur sa capacité à absorber un grand volume d’entrées-sorties aléatoires, à maintenir une latence prévisible et à éviter les pénalités de calcul qui dégradent la réactivité globale de l’infrastructure. C’est précisément sur ce terrain que le RAID 10 se distingue.
Son principe combine deux mécanismes simples : le mirroring, qui duplique les données sur des paires de disques, et le striping, qui répartit les blocs entre plusieurs groupes miroirs. Cette combinaison évite les calculs de parité présents dans d’autres niveaux de RAID, ce qui réduit la pénalité en écriture et simplifie le comportement du volume sous forte sollicitation. Dans une base de données transactionnelle, cette caractéristique est déterminante, car les écritures synchrones, les journaux de transactions, les index et les accès concurrents exposent immédiatement les limites d’une baie mal adaptée. Dans un cluster de virtualisation, la situation est similaire : plusieurs machines virtuelles génèrent simultanément des lectures et écritures aléatoires, avec des profils de charge parfois imprévisibles.
Le RAID 10 est donc souvent retenu lorsque la priorité n’est pas l’optimisation maximale de la capacité utile, mais la continuité de service, la stabilité des temps de réponse et la capacité à encaisser des charges mixtes sans dégradation brutale. Le mot-clé principal RAID 10 s’impose ici naturellement, car il décrit un compromis clairement orienté vers la performance soutenue et la disponibilité. Dans les projets de RAID 10 virtualisation ou de RAID 10 bases de données, le coût supérieur par téraoctet est accepté lorsque le ralentissement d’une charge critique, la prolongation des temps de reconstruction ou l’impact d’une panne sur la production représenteraient un risque plus élevé que la perte de capacité brute. C’est cette logique d’arbitrage technique qui explique sa présence récurrente dans les environnements IT B2B sensibles.
Quels types de charges profitent réellement du RAID 10 ?
Les charges qui tirent le meilleur parti d’un RAID 10 sont celles qui combinent un fort volume d’IO aléatoires, une concurrence élevée et une exigence de régularité dans les temps de réponse. Les bases de données relationnelles en production en font partie, en particulier lorsqu’elles exécutent un grand nombre de transactions courtes, de lectures indexées, d’écritures de journaux et d’opérations simultanées sur plusieurs tables. Dans ce contexte, le comportement du sous-système disque influence directement le temps de validation des transactions, le verrouillage applicatif et la fluidité globale de la plateforme. Le RAID 10 performances répond bien à cette contrainte parce qu’il distribue la charge sur plusieurs disques sans introduire de calcul de parité pénalisant.
La virtualisation constitue un second cas d’usage très favorable. Sur un hôte Hyper-V, VMware ou Proxmox, plusieurs machines virtuelles se partagent la même couche de stockage avec des profils hétérogènes : serveur SQL, contrôleur de domaine, applicatif métier, serveur de fichiers ou middleware. Cette agrégation de petites IO aléatoires crée un phénomène de contention qui défavorise les RAID à parité lorsque les écritures deviennent soutenues. Avec le RAID 10, la baie absorbe mieux les pics mixtes lecture-écriture et conserve une latence plus prévisible.
D’autres charges bénéficient aussi de cette architecture : systèmes OLTP, journaux applicatifs intensifs, environnements VDI, caches transactionnels, plateformes ERP ou messageries d’entreprise avec forte activité. À l’inverse, pour de l’archivage, du partage documentaire peu sollicité ou de la sauvegarde avec écriture majoritairement séquentielle, l’avantage du RAID 10 devient moins décisif. Le gain réel apparaît surtout lorsque l’infrastructure dépend d’une réponse rapide et régulière du stockage pour maintenir les performances applicatives.
Pourquoi les IOPS et la latence sont-elles déterminantes dans ces environnements ?
Dans les environnements de bases de données et de virtualisation, le volume de données total n’est pas l’indicateur le plus critique. Ce qui détermine la perception réelle de performance, ce sont les IOPS disponibles et surtout la latence associée à chaque opération. Une base de données peut rester modérément dimensionnée en capacité tout en générant une pression très forte sur le stockage si elle manipule un grand nombre de petites lectures et écritures aléatoires. Même logique en virtualisation : plusieurs machines virtuelles exécutant des tâches ordinaires peuvent, ensemble, saturer rapidement une baie incapable d’absorber ces accès concurrents.
Les IOPS mesurent la quantité d’opérations que le système peut traiter, mais cette valeur n’a de sens qu’accompagnée d’une latence stable. Un niveau élevé d’IOPS avec des temps de réponse irréguliers dégrade les transactions, provoque des files d’attente et ralentit les services les plus sensibles. Or le RAID 10 limite certaines causes structurelles de latence, car il n’impose pas de lecture-modification-réécriture de parité en écriture. Il réduit donc la pénalité liée aux accès aléatoires et offre un comportement plus linéaire sous charge. C’est une raison centrale de son adoption dans les architectures où l’on cherche une vraie RAID 10 résilience opérationnelle, c’est-à-dire non seulement la survie à la panne, mais aussi la capacité à continuer à délivrer des performances utilisables pendant un incident ou une reconstruction.
Dans un arbitrage RAID 10 vs RAID 5, cette différence devient visible dès que les charges sont transactionnelles. Un stockage techniquement disponible mais trop lent produit des effets comparables à une indisponibilité partielle : services applicatifs ralentis, sessions dégradées, fenêtres batch allongées et consolidation plus difficile des machines virtuelles. C’est pourquoi, dans ces environnements, les IOPS et la latence ne sont pas des métriques secondaires. Elles conditionnent directement le dimensionnement, la stabilité de production et le choix du niveau de RAID.
Comment le RAID 10 améliore-t-il les performances en lecture et en écriture ?
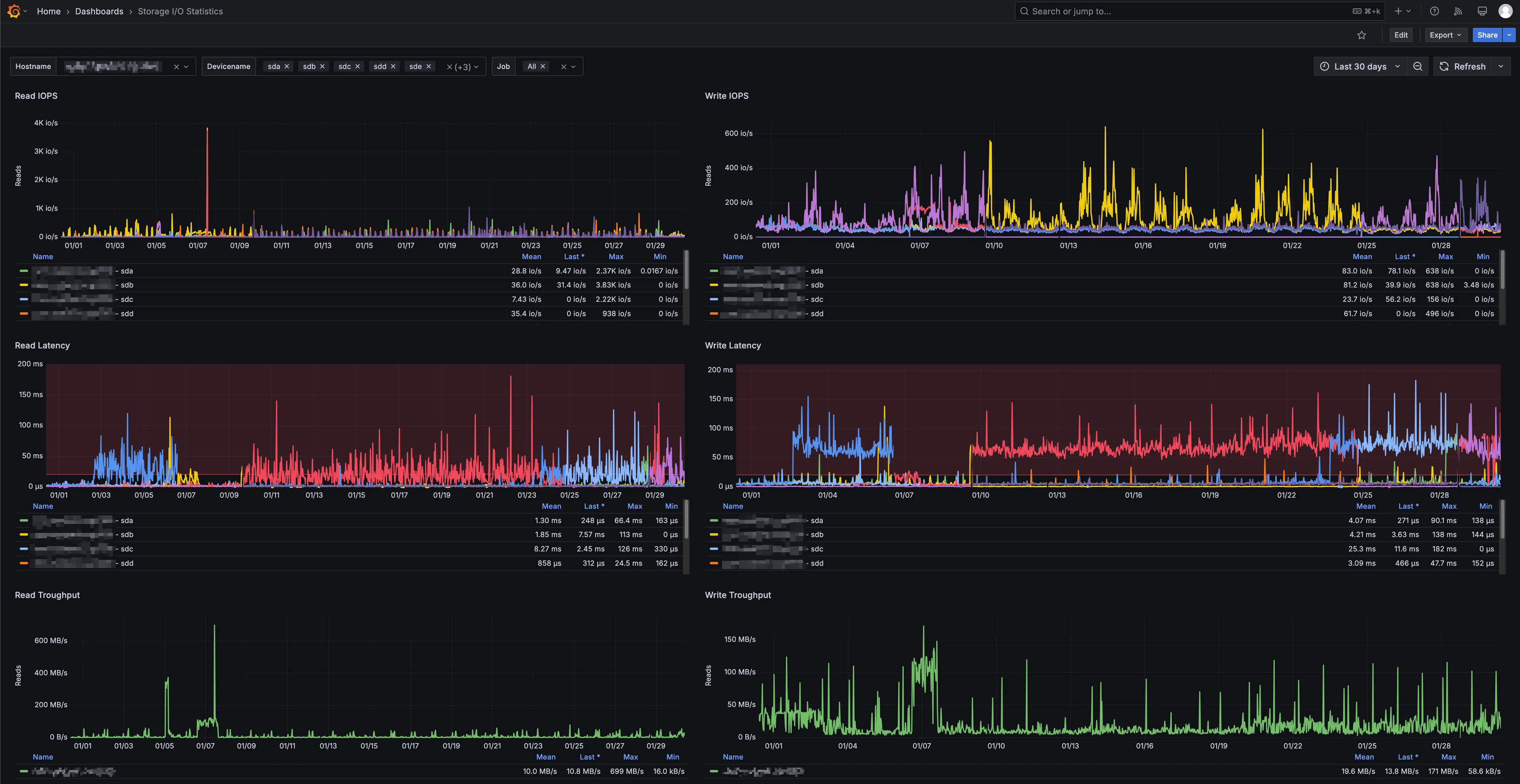
Le RAID 10 améliore les performances en lecture et en écriture en combinant deux propriétés physiques du stockage distribué : la répartition des accès entre plusieurs disques et l’absence de calcul de parité. Dans un environnement professionnel, cette combinaison produit un comportement plus stable que les niveaux de RAID orientés capacité. Lorsqu’un volume doit absorber des flux transactionnels, des mises à jour fréquentes de blocs, des lectures concurrentes et des écritures synchrones, la structure interne du RAID devient un facteur déterminant. Le RAID 10 répond à cette contrainte en évitant les opérations additionnelles qui alourdissent les cycles d’écriture sur les architectures à parité.
En lecture, les données étant présentes sur plusieurs miroirs, le contrôleur peut répartir les requêtes sur différents disques et exploiter le parallélisme disponible. Cette distribution améliore le débit global et surtout la capacité à traiter plusieurs accès simultanés, ce qui est particulièrement utile lorsque plusieurs machines virtuelles ou plusieurs sessions applicatives sollicitent les mêmes ensembles de données. En écriture, le fonctionnement est plus direct que sur un RAID 5 ou un RAID 6 : il n’est pas nécessaire de recalculer une parité ni de réécrire des blocs de contrôle. Chaque écriture doit être dupliquée sur les membres du miroir, mais la logique reste plus simple et plus prévisible sous charge soutenue.
Les RAID 10 performances sont donc surtout visibles quand l’infrastructure travaille sur de petites IO aléatoires, avec un mélange de lectures et d’écritures. Dans ce cas, le stockage doit répondre vite, souvent, et sans dérive de latence. Les chiffres théoriques de débit séquentiel ne suffisent pas à caractériser l’intérêt du RAID 10. Ce qui compte en production, c’est sa capacité à maintenir un niveau d’IOPS élevé avec une latence limitée quand plusieurs processus se disputent la même baie. Cette architecture n’annule pas les besoins en dimensionnement correct du contrôleur, du cache, de l’interconnexion ou du type de disques utilisés, mais elle fournit une base plus favorable pour les environnements où la régularité de réponse vaut souvent plus qu’une capacité brute optimisée.
Comparaison indicative du comportement en lecture et en écriture selon le niveau de RAID sur une charge mixte aléatoire.
Quel impact le striping et le mirroring ont-ils sur les performances ?
Le striping et le mirroring jouent des rôles complémentaires dans le comportement du RAID 10. Le striping répartit les blocs de données entre plusieurs paires de disques, ce qui permet de paralléliser les accès et d’augmenter le nombre d’opérations traitées simultanément. Plus le nombre de paires disponibles est cohérent avec la charge, plus la distribution du travail réduit les points de contention. Cette mécanique améliore aussi bien les lectures multiples que les écritures réparties, à condition que le contrôleur et l’interconnexion suivent le rythme imposé par la couche disque.
Le mirroring, de son côté, apporte deux bénéfices. D’abord, il permet de lire depuis plusieurs copies d’un même bloc, ce qui donne au système davantage de souplesse pour équilibrer certaines requêtes. Ensuite, il supprime le coût algorithmique de la parité. En pratique, cela réduit la pénalité d’écriture observée sur les niveaux de RAID qui doivent recalculer et propager des informations de protection à chaque modification de données. Le résultat n’est pas simplement un gain de vitesse brute. C’est surtout une amélioration de la constance opérationnelle, élément critique pour les applications sensibles à la latence.
Dans une analyse RAID 10 vs RAID 5, c’est précisément cette interaction entre striping et mirroring qui explique l’écart observé sur les écritures aléatoires, les pics de transactions et les charges mixtes. Le RAID 10 n’est pas automatiquement le plus rentable en capacité, mais il offre une structure plus favorable aux environnements où la performance réelle dépend du temps de réponse et non du seul volume stocké.
Le RAID 10 est-il pertinent pour les transactions intensives et les machines virtuelles ?
Le RAID 10 est particulièrement pertinent pour les transactions intensives et les machines virtuelles, car ces deux usages exercent une pression proche sur le stockage : nombreuses IO de petite taille, accès aléatoires, écritures fréquentes et exigences de latence faibles. Une base de données transactionnelle ne souffre pas seulement d’un manque de débit. Elle souffre surtout lorsque les écritures se rallongent, que les journaux attendent le commit disque et que les files d’attente augmentent. Dans ce cadre, l’absence de parité et la répartition des accès rendent le RAID 10 plus adapté qu’un RAID orienté capacité.
Pour la virtualisation, l’intérêt est similaire mais encore plus visible lorsque plusieurs VM partagent le même datastore. Chaque machine virtuelle génère son propre profil d’IO et l’agrégation de ces charges produit un schéma souvent irrégulier. Le stockage doit donc absorber des pointes brutales sans effondrement de latence. Le RAID 10 virtualisation est souvent retenu pour cette raison : il gère mieux la concurrence d’accès et limite les pénalités sur les écritures aléatoires qui dégradent fortement l’expérience applicative.
Cela ne signifie pas qu’il constitue l’unique réponse. Des SSD performants, un cache bien dimensionné, un réseau de stockage cohérent et un hyperviseur correctement configuré restent indispensables. En revanche, lorsque l’on cherche un niveau de RAID capable d’accompagner durablement des charges transactionnelles, des SQL Server, des bases PostgreSQL, des VM applicatives ou des environnements VDI, le RAID 10 reste l’un des choix les plus cohérents sur le plan technique, même lorsque son coût utile est plus élevé.
Latence moyenne indicative observée lorsque le nombre de machines virtuelles actives augmente sur un même volume de stockage.
Quel niveau de résilience le RAID 10 apporte-t-il face aux pannes de disques ?
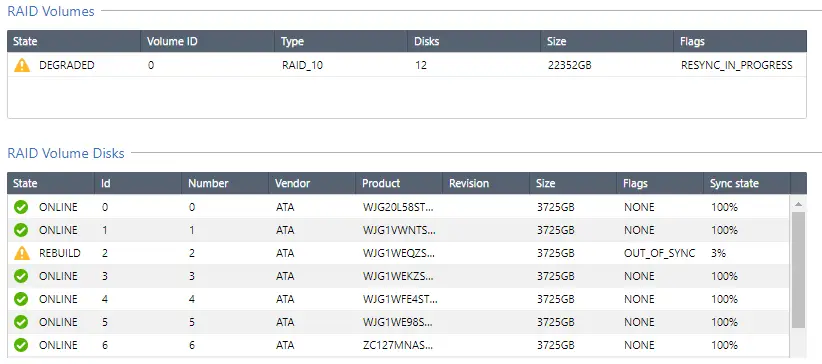
Le RAID 10 est souvent retenu pour sa capacité à maintenir la production malgré une ou plusieurs défaillances matérielles, mais sa résilience doit être comprise avec précision. Il ne s’agit pas d’une protection absolue. Il s’agit d’une architecture fondée sur des paires miroir, ensuite agrégées en striping, ce qui signifie que la tolérance aux pannes dépend directement de la localisation exacte des disques défaillants. Cette nuance est essentielle en environnement B2B, car elle conditionne la façon de dimensionner une baie, d’organiser les groupes de disques et de planifier les opérations de maintenance.
Dans un RAID 10, chaque bloc de données existe sur deux disques appartenant à une même paire miroir. Si un disque tombe en panne, l’autre membre de la paire continue à fournir les données sans interruption logique du volume. Tant qu’une seule unité par miroir est perdue, l’ensemble reste disponible. C’est l’un des points forts de la RAID 10 résilience : la continuité de service peut être préservée sans entrer immédiatement dans une situation critique sur tout le groupe, contrairement à certaines architectures où une panne place l’ensemble du volume dans une fenêtre de vulnérabilité plus large et plus longue.
Cette approche présente aussi un avantage pendant la reconstruction. Le processus de rebuild consiste principalement à recopier les données du disque survivant vers un disque de remplacement, sans recalcul massif de parité. La charge de reconstruction reste donc plus ciblée et généralement plus prévisible. Dans une infrastructure de virtualisation ou de bases de données, cela limite en partie la dégradation des performances pendant la remise en conformité, ce qui compte autant que la simple survie à la panne. En pratique, le RAID 10 réduit le risque d’exposition prolongée à une seconde défaillance lors d’une reconstruction lourde.
Il faut toutefois rappeler qu’un RAID 10 ne protège ni contre la corruption logique, ni contre une suppression applicative, ni contre une erreur humaine, ni contre une panne du contrôleur si l’architecture n’a pas été conçue avec redondance suffisante. Sa résilience concerne avant tout la disponibilité des données face à la panne physique des disques. Pour un décideur technique, cela signifie que le RAID 10 doit être considéré comme un maillon de disponibilité locale, non comme un substitut à la sauvegarde, à la réplication ou au plan de reprise.
Combien de disques peuvent tomber en panne sans perte de données ?
La réponse exacte dépend de la répartition des pannes dans les paires miroir. Théoriquement, un RAID 10 peut tolérer plusieurs défaillances simultanées, à condition qu’aucune paire ne perde ses deux membres. Sur un ensemble de huit disques organisé en quatre miroirs, il serait possible de perdre jusqu’à quatre disques sans perte de données si chaque disque défaillant appartient à une paire différente. En revanche, la perte de deux disques appartenant au même miroir entraîne immédiatement l’indisponibilité du volume et la perte logique des données sur l’ensemble du groupe.
C’est ce point qui différencie le RAID 10 d’une lecture simpliste du nombre de disques tolérés. Il ne faut jamais raisonner uniquement en quantité. Il faut raisonner en topologie. Deux pannes peuvent être supportées dans certains cas et catastrophiques dans d’autres. Cette dépendance structurelle impose une surveillance précise de l’état des disques, une politique de remplacement rapide et un suivi strict des alertes SMART, du contrôleur ou de la baie. En production, la vraie question n’est pas seulement combien de disques peuvent tomber, mais combien de temps une paire miroir reste exposée avant remplacement et reconstruction complète.
Pour les équipes d’exploitation, cette caractéristique rend le RAID 10 plus robuste que ne le suggère parfois une simple lecture des fiches techniques, mais aussi plus exigeant dans la gestion du risque. Une mauvaise appréciation de la cartographie des miroirs peut conduire à sous-estimer la criticité d’une seconde panne survenant au mauvais endroit. La résilience du RAID 10 est donc élevée, mais elle reste conditionnelle.
Quelles sont les limites réelles du RAID 10 en production ?
La principale limite du RAID 10 en production est qu’il peut donner une impression de sécurité supérieure à sa portée réelle. Il tolère bien les défaillances de disques, mais il ne répond pas à l’ensemble des risques qui affectent une plateforme critique. Une corruption du système de fichiers, une erreur de manipulation, une suppression applicative, un ransomware, une panne logicielle de l’hyperviseur ou une défaillance d’alimentation mal maîtrisée ne sont pas neutralisés par le niveau de RAID. Le RAID 10 améliore la disponibilité locale du stockage. Il ne remplace ni la sauvegarde, ni l’immutabilité, ni la réplication distante.
Une autre limite concerne le coût de capacité, qui réduit parfois le nombre de disques réellement déployés dans un budget donné. Or moins il y a de paires miroir, moins le parallélisme et la tolérance structurelle sont étendus. Un RAID 10 sous-dimensionné peut donc être performant sur le papier mais trop étroit pour encaisser durablement la croissance des charges. Il faut aussi intégrer les effets de reconstruction sur des supports de grande capacité. Même si le rebuild est plus simple que sur un RAID à parité, il mobilise fortement le disque survivant du miroir et peut exposer un point de faiblesse si le remplacement n’est pas immédiat.
Enfin, le RAID 10 n’est pas toujours le meilleur choix lorsque l’objectif prioritaire est la densité utile, l’archivage ou la conservation de volumes massifs peu sollicités. Sa logique est clairement orientée vers la performance et la disponibilité. En production, sa limite n’est donc pas une faiblesse intrinsèque, mais le fait qu’il doit être employé pour les bons usages, avec une stratégie complète de protection des données autour de lui.
Comparaison indicative entre temps de reconstruction et niveau d’exposition au risque selon l’architecture RAID.
Quel est le coût réel d’un RAID 10 par rapport aux autres niveaux de RAID ?

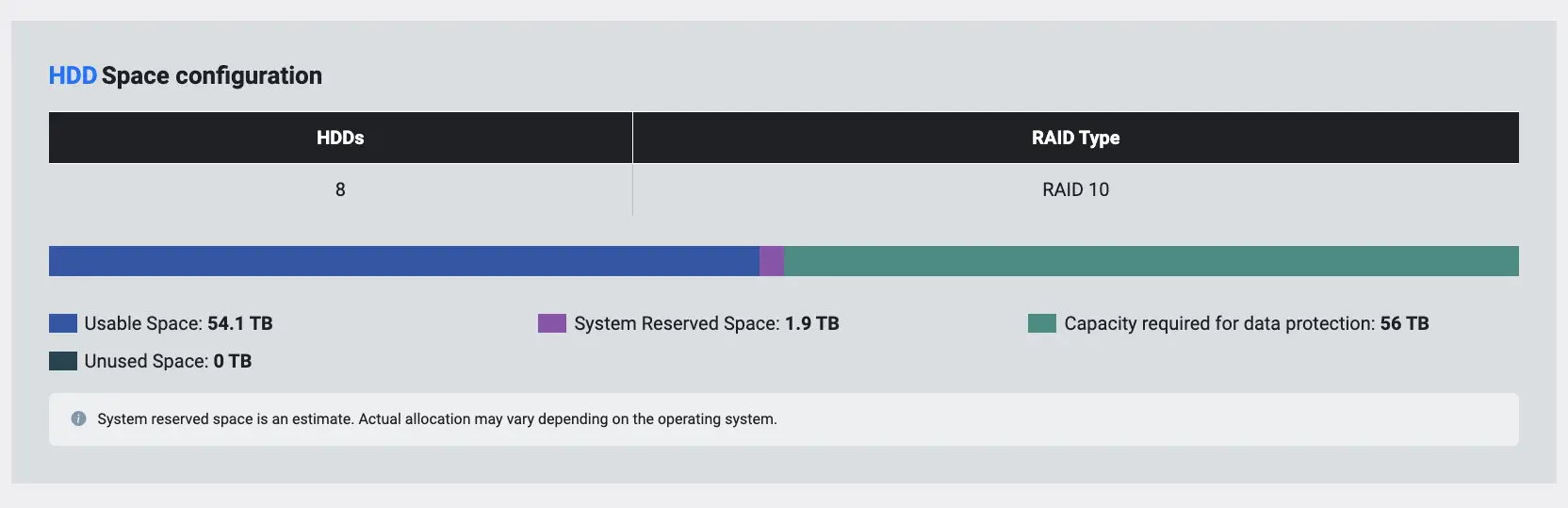
Le coût réel d’un RAID 10 ne se limite pas au prix d’achat des disques. Il résulte d’un arbitrage entre capacité utile, niveau de performance attendu, temps de reconstruction, risque opérationnel et continuité de service. Sur le plan strictement capacitif, le constat est simple : un RAID 10 consacre la moitié de sa capacité brute à la réplication. Avec 8 disques de 3,84 To, la capacité installée atteint 30,72 To bruts, mais la capacité utile exploitable reste proche de 15,36 To avant prise en compte du formatage et des réserves système. Cette caractéristique explique directement pourquoi le RAID 10 coût est généralement supérieur à celui d’un RAID 5 ou d’un RAID 6 à capacité utile équivalente.
Cependant, raisonner uniquement en coût par téraoctet conduit à une analyse incomplète. Dans une infrastructure de production, le stockage doit être évalué selon son coût d’usage réel. Une architecture moins chère mais incapable de maintenir les IOPS requises, de contenir la latence sous charge ou de reconstruire rapidement après panne peut générer un coût global bien plus élevé : ralentissement applicatif, surdimensionnement CPU ou mémoire pour compenser, interruptions de service, fenêtre de vulnérabilité prolongée ou besoin de multiplier les mécanismes correctifs autour de la baie. C’est sur ce terrain que le RAID 10 reprend un avantage rationnel dans certains contextes professionnels.
Dans les environnements de bases de données ou de RAID 10 virtualisation, le prix du stockage doit être comparé au coût d’une dégradation de service. Si un datastore trop lent ralentit plusieurs machines virtuelles critiques, si une base transactionnelle perd en réactivité ou si une reconstruction longue expose l’environnement à un incident secondaire, la différence de coût initial entre niveaux de RAID devient relative. Le RAID 10 n’est donc pas un choix économique au sens de la densité utile, mais il peut être un choix économiquement cohérent au sens du coût global d’exploitation. Cette logique le différencie des niveaux de RAID à parité, plus efficaces en capacité, mais pas toujours alignés avec les charges où la performance stable et la disponibilité immédiate ont une valeur supérieure au volume brut installé.
Pourquoi le coût utile par téraoctet est-il plus élevé ?
Le coût utile par téraoctet est plus élevé en RAID 10 parce que la moitié de la capacité brute est immobilisée par le mirroring. Chaque donnée écrite sur un disque est reproduite sur son disque jumeau, ce qui signifie qu’un environnement nécessitant 20 To utiles doit en réalité déployer environ 40 To bruts, hors marges supplémentaires. À matériel identique, cette architecture exige donc davantage de disques, davantage d’emplacements occupés, parfois plus de tiroirs, plus de consommation électrique et potentiellement davantage de maintenance matérielle. Ce surcoût est structurel. Il ne résulte pas d’un mauvais dimensionnement mais du principe même du RAID 10.
Par comparaison, un RAID 5 ou un RAID 6 mutualise une partie de la protection via la parité et conserve une part bien plus élevée de capacité utile. Le coût apparent par téraoctet devient alors nettement plus favorable. C’est la raison pour laquelle les infrastructures orientées archivage, sauvegarde sur disque ou conservation de gros volumes peu transactionnels évitent souvent le RAID 10. Dans ces cas, la priorité est la densité utile, non la latence minimale.
Le calcul doit aussi intégrer les effets indirects. Si le RAID 10 demande plus de capacité brute, il peut parfois éviter d’autres dépenses, par exemple l’ajout de disques uniquement pour augmenter les performances ou la mise en place de couches de cache plus agressives afin de masquer les limites d’un RAID à parité. Le coût utile est donc objectivement plus élevé, mais son impact doit être lu dans l’ensemble de l’architecture et pas seulement au niveau du prix brut des supports.
Dans quels cas ce surcoût reste-t-il justifié ?
Le surcoût du RAID 10 reste justifié lorsque la performance réelle du stockage a un effet direct sur la continuité d’activité ou sur la qualité de service rendue par l’infrastructure. C’est le cas des bases de données transactionnelles, des ERP, des systèmes de réservation, des plateformes de virtualisation hébergeant des services métiers critiques, des environnements VDI intensifs ou des applications dont les écritures synchrones sont nombreuses. Dans ces scénarios, la valeur ne réside pas dans l’optimisation maximale de la capacité, mais dans la capacité à maintenir une latence basse, des RAID 10 performances constantes et une reconstruction plus rapide après incident.
Le surcoût est également défendable lorsqu’il permet d’éviter une multiplication de risques techniques. Un RAID à parité peut être moins cher à l’achat, mais devenir plus coûteux si les temps de reconstruction s’allongent fortement, si les pics d’écriture dégradent l’ensemble des VM ou si l’exploitation doit continuellement contourner les limites de performance de la baie. Dans une logique de coût global, le prix du RAID 10 peut alors être absorbé par la baisse du risque d’indisponibilité, par une meilleure stabilité applicative et par une réduction des incidents liés au stockage.
En revanche, lorsque la charge est majoritairement séquentielle, peu sensible à la latence et fortement orientée capacité, le RAID 10 perd sa justification économique. Le bon choix dépend donc moins du prix facial des disques que de la nature des applications, du niveau de service attendu et du coût réel d’une baisse de performance ou d’une fenêtre de vulnérabilité prolongée.
Comment choisir entre RAID 10, RAID 5 et RAID 6 selon l’usage ?
Le choix entre RAID 10, RAID 5 et RAID 6 ne doit jamais être guidé uniquement par la capacité utile ou par une préférence générique pour un niveau de RAID. Il doit être établi à partir du comportement réel des charges, du niveau de criticité des applications, de la fenêtre de reconstruction acceptable et de l’impact d’une dégradation de performance sur la production. En environnement B2B, un mauvais arbitrage conduit souvent à deux erreurs inverses : surdimensionner un stockage coûteux pour des usages peu exigeants, ou au contraire sous-dimensionner une baie destinée à des applications transactionnelles qui réclament une latence faible et des IOPS stables.
Le RAID 5 reste pertinent lorsque l’objectif principal est de conserver une bonne efficacité de capacité tout en maintenant une protection simple contre la panne d’un disque. Il convient davantage aux charges où les écritures aléatoires intensives restent limitées et où la sensibilité à la latence est modérée. Le RAID 6 ajoute une protection supplémentaire contre la perte simultanée de deux disques, ce qui peut être important sur des ensembles de forte capacité ou lorsque les temps de reconstruction deviennent longs. En contrepartie, il augmente encore la pénalité liée aux écritures et alourdit le comportement sous charge transactionnelle.
Le RAID 10, lui, doit être choisi quand le stockage est directement au service d’applications sensibles au temps de réponse : bases SQL, moteurs transactionnels, hyperviseurs, clusters applicatifs ou environnements où plusieurs charges mixtes coexistent sur la même baie. Dans un arbitrage RAID 10 vs RAID 5, la question centrale n’est donc pas seulement la capacité ou le budget initial. Il faut mesurer ce que coûte une hausse de latence, une reconstruction longue, une saturation en écriture ou une dégradation de service sur les machines virtuelles et les bases de données. Le bon niveau de RAID est celui qui aligne le stockage avec l’usage réel, sans chercher à universaliser une architecture qui resterait excellente dans un cas et inadaptée dans un autre.
Quels critères techniques doivent guider le choix ?
Le premier critère technique est le profil d’IO. Il faut déterminer si la charge est majoritairement séquentielle ou aléatoire, lire le ratio lecture-écriture, mesurer la taille moyenne des blocs et identifier les périodes de pointe. Une charge dominée par de petites écritures aléatoires et des accès simultanés favorise clairement le RAID 10. Une charge plus séquentielle, moins sensible à la latence et orientée capacité peut être compatible avec RAID 5 ou RAID 6. Le second critère concerne le niveau de service attendu : temps de réponse cible, tolérance à la congestion, maintien de performance pendant un rebuild et impact métier d’un ralentissement.
Il faut ensuite intégrer la taille des disques et la durée potentielle de reconstruction. Plus les supports sont volumineux, plus la fenêtre d’exposition après panne s’allonge, ce qui renforce l’intérêt du RAID 6 pour certains usages orientés capacité ou du RAID 10 pour les environnements critiques recherchant une reconstruction plus simple. Le budget ne doit intervenir qu’après cette analyse. Un coût inférieur par téraoctet ne constitue pas un avantage si l’architecture ne tient pas la charge. À l’inverse, un RAID 10 coût supérieur n’est justifié que si les applications exploitent réellement ses qualités structurelles.
Pour quels scénarios le RAID 10 est-il le plus adapté ?
Le RAID 10 est le plus adapté aux scénarios où la performance utile dépend du temps de réponse bien plus que de la capacité brute. C’est le cas des bases de données OLTP, des journaux de transactions, des serveurs SQL ou PostgreSQL fortement sollicités, des plateformes de virtualisation concentrant plusieurs machines critiques sur le même datastore et des environnements VDI avec activité simultanée importante. Dans ces cas, les bénéfices du RAID 10 performances, de la faible pénalité en écriture et d’une meilleure prévisibilité de latence sont immédiatement exploitables.
Il convient aussi aux infrastructures où la disponibilité opérationnelle du stockage doit rester élevée pendant une panne disque et durant la reconstruction. Une architecture de RAID 10 virtualisation ou de RAID 10 bases de données supporte généralement mieux la continuité de service qu’un ensemble à parité fortement sollicité. En revanche, il n’est pas le meilleur choix pour de l’archivage, de la sauvegarde sur disque, du partage de fichiers peu transactionnel ou des volumes massifs où la densité utile prime sur la rapidité de réponse.
Le RAID 10 doit donc être retenu lorsqu’il existe une relation directe entre performance de stockage, qualité de service applicative et réduction du risque technique. Dès que l’usage se déplace vers la capacité optimisée plutôt que vers l’exécution rapide et stable des charges, RAID 5 ou RAID 6 redeviennent plus cohérents.