

Le RAID informatique désigne un ensemble de techniques permettant de regrouper plusieurs disques physiques afin de former un volume logique unique, présenté au système comme une seule entité de stockage. Son objectif principal est d’améliorer la disponibilité des données et, selon le niveau utilisé, les performances d’accès ou la tolérance aux pannes matérielles. Le RAID est largement utilisé dans les infrastructures IT professionnelles, notamment sur les serveurs, les baies de stockage et les plateformes de virtualisation, où l’interruption de service et la perte de données ont des impacts directs sur l’activité. Contrairement à une idée répandue, le RAID ne constitue pas une solution de sauvegarde. Il agit uniquement au niveau de la continuité de service et de la résilience matérielle face à la défaillance d’un ou plusieurs disques. Comprendre ses principes, ses niveaux, ses limites et son positionnement réel est indispensable pour concevoir une architecture de stockage cohérente et maîtrisée.
Qu’est-ce que le RAID en informatique professionnelle ?
Définition technique du RAID
Le RAID repose sur l’agrégation logique de plusieurs disques physiques afin de constituer un volume unique vu par le système d’exploitation ou l’hyperviseur. Cette agrégation s’appuie sur différents mécanismes techniques, principalement le striping, le mirroring et la parité. Le striping répartit les blocs de données sur plusieurs disques pour améliorer les performances, le mirroring duplique les données pour assurer une redondance immédiate, et la parité permet de reconstruire des données en cas de défaillance d’un disque. Le résultat est un volume logique abstrait, indépendant du support physique sous-jacent, dont le comportement dépend directement du niveau RAID choisi. Le RAID agit exclusivement au niveau du stockage et n’intervient ni sur la logique applicative ni sur la protection contre les erreurs logiques.
Origine et évolution du RAID dans les infrastructures IT
Le concept de RAID est apparu à la fin des années 1980 pour répondre aux limites des disques durs individuels en matière de fiabilité et de performance. Initialement utilisé dans les serveurs d’entreprise équipés de disques mécaniques, le RAID s’est progressivement imposé comme un standard dans les centres de données. Avec l’évolution des infrastructures, il s’est adapté aux baies de stockage SAN et NAS, puis aux environnements virtualisés. L’arrivée des SSD et des technologies NVMe a modifié les enjeux de performance, mais le RAID reste pertinent pour la gestion de la disponibilité et la tolérance aux pannes, indépendamment du type de support utilisé.
Différence entre RAID logique et agrégation de disques
Il est essentiel de distinguer le RAID d’une simple agrégation de disques, souvent appelée JBOD. Dans une agrégation simple, les disques sont concaténés ou utilisés indépendamment sans mécanisme de redondance ou de reconstruction. En cas de défaillance, les données associées au disque concerné sont perdues. Le RAID, au contraire, introduit une couche logique qui organise la répartition des données et permet, selon le niveau, de continuer à fonctionner malgré une panne matérielle. Cette différence a un impact direct sur la résilience de l’infrastructure et sur la capacité à maintenir les services en production.
À quoi sert réellement le RAID en environnement de production ?
Continuité de service et tolérance aux pannes
En environnement de production, le RAID est avant tout utilisé pour assurer la continuité de service face aux défaillances matérielles. Lorsqu’un disque tombe en panne, le système peut continuer à fonctionner sans interruption, selon le niveau RAID mis en place. Le volume passe alors en mode dégradé, mais reste accessible pour les applications et les utilisateurs. Cette capacité à absorber une panne matérielle sans arrêt immédiat des services est essentielle dans les infrastructures critiques, où une indisponibilité, même temporaire, peut avoir des conséquences opérationnelles importantes.
Impact du RAID sur les performances applicatives
Pour les écritures, on parle souvent de pénalité d'écriture (write penalty) : c’est le nombre moyen d’opérations disque nécessaires pour réaliser une seule écriture logique. Plus cette pénalité est élevée, plus le système doit effectuer d’entrées/sorties pour écrire la même quantité de données.
Le graphique ci-dessous compare cette pénalité d’écriture relative selon les niveaux RAID les plus courants.
Le RAID peut également influencer les performances des applications, en particulier sur les opérations de lecture et d’écriture. Certains niveaux RAID améliorent les débits en lecture grâce à la répartition des données sur plusieurs disques, tandis que les écritures peuvent être pénalisées par les calculs de parité ou les mécanismes de synchronisation. L’impact réel dépend du type de RAID, de la nature des workloads et du matériel sous-jacent. Le RAID ne doit donc pas être considéré comme un simple accélérateur de performance, mais comme un compromis entre disponibilité, capacité et performances.
Cas d’usage en serveurs, baies de stockage et hyperviseurs
Dans les serveurs physiques, le RAID est souvent utilisé pour sécuriser les volumes systèmes et applicatifs. Dans les baies de stockage, il constitue la base des pools de disques présentés aux serveurs via des protocoles SAN ou NAS. En environnement virtualisé, le RAID est généralement implémenté en amont des hyperviseurs, afin de garantir la disponibilité des datastores hébergeant les machines virtuelles. Dans tous les cas, le RAID intervient comme une couche fondamentale de l’architecture de stockage, sans se substituer aux mécanismes de sauvegarde ou de réplication.
Quels sont les principaux niveaux RAID et leurs caractéristiques ?
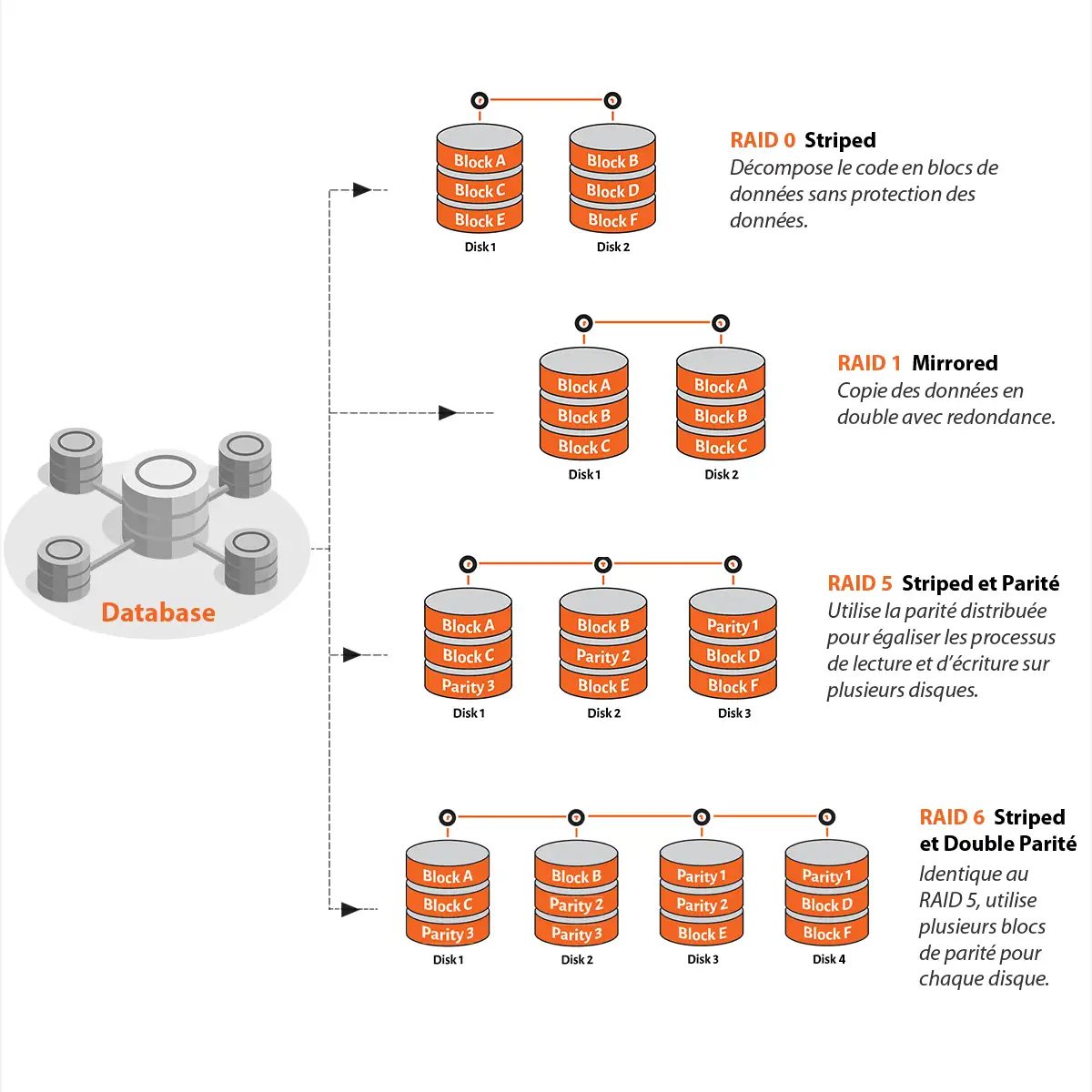
RAID historiques et usages limités en environnements modernes
Les niveaux RAID dits historiques reposent sur des mécanismes simples qui servent encore de bases conceptuelles, mais dont les usages sont aujourd’hui très encadrés. Le RAID 0 repose sur la répartition par bandes (striping), c’est-à-dire la distribution des blocs de données sur plusieurs disques afin d’augmenter les débits. Il n’intègre aucun mécanisme de redondance et la défaillance d’un seul disque entraîne la perte totale des données. Le RAID 1 utilise la mise en miroir (mirroring), chaque donnée étant écrite simultanément sur deux disques distincts, ce qui permet une continuité de service simple mais réduit mécaniquement la capacité exploitable. Le RAID 5 introduit un mécanisme de parité distribuée permettant de reconstruire les données après la perte d’un disque. Dans les environnements modernes utilisant des disques de grande capacité, ce niveau présente des limites importantes : la phase de reconstruction peut durer plusieurs heures, voire plusieurs jours, durant lesquelles les performances chutent fortement et le risque opérationnel augmente. En contexte SAN ou stockage centralisé, le RAID 5 ne constitue plus un choix par défaut et doit être réservé à des scénarios précisément dimensionnés et maîtrisés.
RAID 6, RAID 10, RAID 50 et RAID 60 en infrastructures professionnelles
Le graphique ci-dessous illustre le coût en capacité utile (exemple sur 12 disques).
Hypothèse : 12 disques identiques. RAID 50 = 2 groupes RAID 5 (6 disques). RAID 60 = 2 groupes RAID 6 (6 disques).
Le RAID 6 s’appuie sur un principe de double parité, permettant de tolérer la défaillance simultanée de deux disques. Cette approche est mieux adaptée aux grappes de disques importantes, où le risque de panne multiple durant une reconstruction est réel. Le RAID 10 combine la mise en miroir et la répartition par bandes, offrant à la fois de faibles latences, de bonnes performances en écriture et une forte résilience, au prix d’une consommation de capacité plus élevée. Les niveaux RAID 50 et RAID 60 sont des architectures composées, construites par répartition par bandes au-dessus de plusieurs groupes RAID 5 ou RAID 6. Cette organisation permet de segmenter les reconstructions, de limiter l’impact d’une panne sur l’ensemble du volume et de maintenir des performances acceptables lorsque le nombre total de disques augmente. Ces niveaux sont particulièrement utilisés dans les baies de stockage SAN, où le dimensionnement précis des groupes de disques et la maîtrise des temps de reconstruction sont des paramètres critiques.
RAID logiciel avancé et équivalents ZFS (RAIDZ, RAIDZ2, RAIDZ3)
Dans les architectures basées sur ZFS, on ne parle pas de RAID au sens classique, mais de schémas de redondance intégrés au système de fichiers, appelés RAIDZ, RAIDZ2 et RAIDZ3, correspondant respectivement à un, deux ou trois disques de parité. Ces mécanismes sont intégrés directement au système de fichiers et fonctionnent au niveau des groupes de disques, appelés périphériques virtuels (vdev). ZFS ajoute une couche d’intégrité des données grâce à des sommes de contrôle systématiques, permettant de détecter et corriger certaines corruptions silencieuses. Le dimensionnement se raisonne à l’échelle des groupes de disques et du groupe de stockage global, en tenant compte de la charge applicative, des performances attendues, des temps de reconstruction et du comportement sous contrainte. Dans un contexte de baie SAN ou de stockage entreprise, le choix entre RAIDZ, RAIDZ2, RAIDZ3 ou des groupes en miroir ne relève pas d’une simple préférence, mais d’un arbitrage technique structurant pour la disponibilité et la pérennité des données.
Quelle est la différence entre RAID matériel et RAID logiciel ?
Architecture et rôle du contrôleur RAID matériel
Le RAID matériel repose sur un contrôleur dédié, intégré à une carte ou à une baie de stockage, qui prend en charge l’ensemble des opérations liées à la gestion des disques. Ce contrôleur dispose de ses propres ressources de calcul et, dans de nombreux cas, d’une mémoire cache protégée par batterie ou supercondensateur. Il gère la répartition des données, la parité, la détection des pannes et les opérations de reconstruction sans solliciter directement le système d’exploitation. Cette approche permet une isolation claire entre la couche de stockage et la couche logicielle, ce qui améliore la prévisibilité des performances et la stabilité globale de l’infrastructure. En environnement SAN ou en baie de stockage professionnelle, le RAID matériel constitue souvent la fondation sur laquelle reposent les volumes présentés aux serveurs.
RAID logiciel au niveau système et hyperviseur
Le RAID logiciel est implémenté directement au niveau du système d’exploitation ou de l’hyperviseur. Les mécanismes de protection et de répartition des données sont alors assurés par des composants logiciels, qui utilisent les ressources CPU et mémoire du serveur. Cette approche offre une grande souplesse de configuration et une meilleure portabilité, notamment dans les environnements virtualisés ou hyperconvergés. En contrepartie, les performances et la résilience dépendent fortement de la charge globale du système et de la qualité de l’implémentation logicielle. Le RAID logiciel est couramment utilisé dans les architectures modernes, y compris avec des systèmes de fichiers avancés comme ZFS, mais il nécessite un dimensionnement précis pour éviter les effets de contention.
Avantages, limites et impacts sur la résilience
Le choix entre RAID matériel et RAID logiciel ne peut pas être tranché de manière universelle. Le RAID matériel apporte une séparation nette des responsabilités et une stabilité appréciable dans les infrastructures critiques, mais il introduit une dépendance forte au matériel et à son cycle de vie. Le RAID logiciel, plus flexible, facilite l’évolution des architectures et l’intégration avec des solutions de stockage définies par logiciel, mais expose davantage aux erreurs de configuration et aux surcharges système. En termes de résilience, les deux approches peuvent offrir un niveau élevé de tolérance aux pannes si elles sont correctement mises en œuvre. La décision doit donc s’appuyer sur le contexte d’exploitation, les exigences de performance, la stratégie de maintenance et les compétences disponibles pour opérer l’infrastructure.
Quelles sont les limites du RAID face aux risques modernes ?
RAID et perte logique de données
Le RAID protège contre certaines défaillances matérielles, mais il n’apporte aucune protection face aux pertes logiques de données. Une suppression accidentelle, une erreur applicative ou une corruption logique est immédiatement répliquée sur l’ensemble des disques composant le volume RAID. Le mécanisme de redondance, conçu pour assurer la disponibilité, devient alors un facteur aggravant, car l’erreur est propagée sans possibilité de retour en arrière. Le RAID ne conserve aucun historique des versions et ne permet pas de restaurer un état antérieur des données. Cette limite est fondamentale et doit être clairement comprise lors de la conception d’une architecture de stockage professionnelle.
RAID face aux pannes multiples et erreurs humaines
Dans les environnements modernes utilisant des disques de grande capacité, le risque de pannes multiples ne peut pas être négligé. Lorsqu’un disque tombe en panne, le volume entre en phase de reconstruction, période durant laquelle les autres disques sont fortement sollicités. Cette charge accrue augmente la probabilité d’une seconde défaillance, en particulier sur des grappes importantes. À cela s’ajoutent les erreurs humaines, comme le retrait du mauvais disque ou une mauvaise manipulation lors d’une intervention. Le RAID ne protège pas contre ces scénarios, et une erreur d’exploitation peut entraîner une indisponibilité majeure, voire une perte définitive des données.
RAID et ransomware : ce qu’il ne protège pas
Face aux attaques par rançongiciel, le RAID n’apporte aucune protection spécifique. Si un système est compromis, le chiffrement des données est appliqué au niveau logique et se propage instantanément à l’ensemble du volume RAID. La redondance ne joue alors aucun rôle protecteur et peut même accélérer la propagation du sinistre. Le RAID ne permet ni de bloquer l’attaque, ni de restaurer les données dans leur état antérieur. Dans un contexte de menaces modernes, il doit impérativement être complété par des mécanismes indépendants, tels que des sauvegardes isolées, des snapshots protégés ou des stratégies de restauration éprouvées.
Comment positionner le RAID dans une stratégie globale de sauvegarde ?
Complémentarité entre RAID et sauvegarde
Le RAID et la sauvegarde répondent à des objectifs fondamentalement différents et ne doivent jamais être confondus. Le RAID vise à assurer la disponibilité immédiate des données en cas de défaillance matérielle, tandis que la sauvegarde a pour but de permettre une restauration après un incident logique, une erreur humaine ou une compromission du système. Le RAID agit en temps réel sur les disques actifs, alors que la sauvegarde introduit une copie indépendante, stockée sur un autre support ou dans un autre emplacement. Dans une architecture professionnelle, le RAID constitue donc une couche de continuité de service, mais il ne remplace en aucun cas une politique de sauvegarde structurée et régulièrement testée.
RAID, snapshots et réplication
Les snapshots et la réplication sont souvent associés au RAID dans les infrastructures de stockage modernes, mais ils ne couvrent pas les mêmes risques. Les snapshots permettent de figer l’état des données à un instant donné, facilitant un retour en arrière rapide en cas d’erreur récente. Toutefois, lorsqu’ils sont stockés sur le même système, ils restent exposés aux mêmes risques physiques et logiques. La réplication consiste à maintenir une copie synchronisée ou asynchrone des données sur un autre site ou un autre système, améliorant la résilience face aux pannes majeures. Ces mécanismes complètent le RAID, mais ne remplacent pas des sauvegardes isolées, capables de résister à des scénarios de compromission globale.
Bonnes pratiques en infrastructures professionnelles
Dans une infrastructure IT professionnelle, le positionnement du RAID doit s’inscrire dans une approche globale de protection des données. Cela implique une séparation claire des rôles entre disponibilité, performance et restauration. Les sauvegardes doivent être stockées sur des supports distincts, idéalement déconnectés ou protégés contre les accès non autorisés. Les procédures de restauration doivent être documentées et régulièrement testées afin de garantir leur efficacité en situation réelle. Le RAID, correctement dimensionné et surveillé, constitue une base solide, mais il ne prend tout son sens que lorsqu’il est intégré dans une stratégie cohérente incluant sauvegarde, réplication et supervision continue.