

La règle de sauvegarde 3-2-1 reste la base de toute stratégie de protection des données sérieuse, mais elle doit aujourd’hui être renforcée pour faire face aux ransomwares et aux architectures hybrides. L’article détaille d’abord le fonctionnement concret de 3-2-1 (copies, supports, hors site) et ses apports en termes de continuité d’activité et de plan de reprise après sinistre. Il analyse ensuite ses limites quand toutes les copies restent en ligne ou dépendent de la même infrastructure, puis explique comment les attaquants ciblent désormais directement les systèmes de sauvegarde. La variante 3-2-1-1-0, le stockage immuable, la bande LTO hors ligne et le stockage objet sont présentés comme des briques clés pour renforcer la résilience. Enfin, l’article aborde l’adaptation de ces principes aux environnements cloud et aux contraintes réglementaires, ainsi que les indicateurs et tests de restauration à suivre pour valider l’efficacité réelle de la stratégie.
Qu’est-ce que la stratégie de sauvegarde 3-2-1 et pourquoi reste-t-elle une référence en 2025 ?

Définition détaillée des trois copies de données dans la règle 3-2-1
La stratégie de sauvegarde 3-2-1 définit une règle simple : disposer d’au moins trois copies de vos données, stockées sur deux types de supports distincts, dont au moins une copie hors site. Cette approche structure une politique de sauvegarde cohérente en réduisant au maximum les points de défaillance communs entre production, sauvegarde locale et sauvegarde distante.
Les trois copies correspondent généralement aux données de production et à deux jeux de sauvegarde. La première copie de sauvegarde est souvent stockée sur un support rapide et proche de la production, par exemple une baie de disques, un NAS ou une appliance de sauvegarde. Elle sert aux restaurations fréquentes et aux incidents du quotidien : suppression accidentelle, corruption d’un fichier, défaillance ponctuelle d’un volume.
Utilisation de deux supports de stockage distincts pour limiter les risques communs
Le deuxième jeu de sauvegarde vise la résilience à moyen et long terme. Il peut être stocké sur un autre média, comme une bande LTO, du stockage objet ou une autre baie de disques, et dans une autre zone logique. L’objectif est d’éviter qu’une panne matérielle, une erreur de configuration ou un incident électrique ne compromette simultanément toutes les copies.
L’utilisation de deux supports de stockage distincts limite les risques dits de mode commun. En pratique, combiner disque et bande, ou disque et stockage objet, permet de diversifier les technologies, les chaînes logicielles et les modes d’accès. Cette diversité rend plus difficile la compromission globale du système de sauvegarde par un même incident, qu’il soit physique, logique ou logiciel.
Principe et objectifs de la copie hors site dans les environnements professionnels
La copie hors site constitue le dernier filet de sécurité. Elle doit être située dans un autre bâtiment, un autre datacenter ou une région cloud différente. Son rôle est de protéger l’organisation contre les sinistres majeurs : incendie, inondation, vol, panne électrique de grande ampleur, voire indisponibilité prolongée d’un site. Sans cette copie distante, un incident local sévère peut entraîner une perte de données irréversible malgré la présence de multiples copies sur site.
Positionnement de la règle 3-2-1 par rapport aux autres approches de sauvegarde
Par rapport à d’autres approches de sauvegarde plus récentes, la règle 3-2-1 reste une base de référence précisément parce qu’elle est indépendante des technologies. Elle s’applique aussi bien à un environnement entièrement sur site qu’à une architecture hybride ou cloud. Les variantes modernes comme 3-2-1-1-0 ou 4-3-2 ne remplacent pas ce socle : elles l’enrichissent pour mieux prendre en compte les ransomwares, la croissance des volumes de données et les exigences réglementaires actuelles.
Pourquoi adopter la règle 3-2-1 dans une infrastructure informatique professionnelle ?
Gestion des risques de perte de données et principaux scénarios d’incident
Dans une infrastructure professionnelle, la règle de sauvegarde 3-2-1 répond d’abord à un objectif de maîtrise du risque. Un système d’information cumule serveurs physiques, machines virtuelles, bases de données, partages de fichiers et applications métiers, autant de points de défaillance possibles : panne de baie de disques, corruption logique progressive, erreur de suppression, mise à jour défectueuse ou incident électrique. En imposant trois copies sur au moins deux supports distincts, dont une hors site, la stratégie 3-2-1 réduit fortement la probabilité qu’un même événement supprime toutes les données disponibles.
Contribution à la continuité d’activité et au plan de reprise après sinistre
La sauvegarde ne sert pas uniquement à restaurer un fichier isolé ; elle est un pilier du plan de reprise après sinistre (PRA). Une architecture 3-2-1 bien définie permet de reconstruire rapidement des services critiques complets — serveurs applicatifs, bases de données, environnements de virtualisation, espaces de travail — en s’appuyant sur des copies réparties entre stockage local rapide, site secondaire et emplacement hors site. Les objectifs de point de reprise (RPO) et les objectifs de temps de reprise (RTO) peuvent ainsi être adaptés à la criticité des applications, avec des sauvegardes locales fréquentes pour les services sensibles et des répliques plus espacées pour les systèmes de support.
Conformité, exigences métiers et justification budgétaire
De nombreux secteurs imposent des exigences explicites en matière de sauvegarde et de rétention des données : réglementation financière, dossiers de santé, obligations du secteur public ou de l’industrie critique. Les référentiels comme ISO 27001 ou ISO 22301 insistent sur la capacité à restaurer les informations essentielles dans des délais maîtrisés. La règle 3-2-1 fournit un langage compréhensible par les auditeurs et les métiers, tout en restant compatible avec des architectures complexes. En documentant supports, emplacements, durées de rétention et fréquence des tests de restauration, l’organisation peut justifier ses investissements en stockage, bande passante et licences logicielles sur une base factuelle.
Intégration avec les systèmes de stockage existants
La mise en œuvre de 3-2-1 s’appuie généralement sur les briques déjà présentes : baies SAN, NAS de fichiers, bibliothèques de bandes LTO, appliances de sauvegarde sur disque ou stockage objet. La plupart des solutions de sauvegarde d’entreprise savent orchestrer plusieurs cibles et plusieurs sites ; l’enjeu principal consiste à cartographier les flux de données et à affecter chaque type de donnée à une politique cohérente avec la règle. Une fois cette cartographie réalisée, 3-2-1 devient un fil directeur lisible pour les équipes d’exploitation, la direction des systèmes d’information et les métiers, facilitant les arbitrages entre performance, coûts et contraintes réglementaires.
Comment appliquer concrètement la règle de sauvegarde 3-2-1 dans une infrastructure de production ?

Répartition des copies entre stockage primaire, secondaire et hors site
La mise en œuvre concrète de la stratégie de sauvegarde 3-2-1 commence par une cartographie précise des données de production : serveurs applicatifs, bases de données, partages de fichiers, environnements de virtualisation, services bureautiques et applications métiers. Le stockage primaire héberge les données actives, généralement sur des baies SAN ou NAS hautes performances, parfois complétées par du SSD pour les applications les plus sensibles à la latence.
Le stockage secondaire est conçu pour des restaurations rapides. Il s’agit le plus souvent d’un disque dédié à la sauvegarde (appliance ou serveur de sauvegarde), capable d’absorber des flux importants pendant les fenêtres de sauvegarde et de restituer rapidement des volumes complets en cas d’incident. La troisième copie, hors site, est positionnée dans un autre bâtiment, un datacenter distant ou une région cloud distincte. Elle est optimisée pour la résilience plutôt que pour la vitesse, avec des politiques de rétention plus longues et des coûts de stockage au gigaoctet plus compétitifs.
Choix des supports de sauvegarde : disque, bande LTO, SSD et stockage objet
Pour le stockage secondaire sur site, le disque reste le support le plus courant : baies de disques SATA ou NL-SAS, appliances de sauvegarde dédiées ou NAS de grande capacité. Les SSD sont réservés à des cas particuliers où les fenêtres de sauvegarde sont très contraintes ou lorsque des restaurations fréquentes de machines virtuelles complètes sont nécessaires. Pour la copie hors site, la bande LTO reste une option très pertinente : coût par téraoctet faible, compatibilité avec une stratégie hors ligne ou air-gapped, et possibilité de stocker physiquement les cartouches dans un site sécurisé.
Le stockage objet, qu’il soit on-premise ou dans le cloud, s’impose de plus en plus comme support de sauvegarde distant. Il offre une très bonne scalabilité, des modèles de tarification adaptés aux grands volumes et, dans sa version immuable, une protection renforcée contre la suppression et la modification non autorisée des sauvegardes. Une architecture hybride combinant disque local, bande LTO et stockage objet permet de tirer parti des points forts de chaque technologie dans le cadre de la règle 3-2-1.
Exemple de répartition des fréquences de sauvegarde
Le graphique ci-dessous illustre une stratégie type où la fréquence des sauvegardes varie selon la criticité des données et le type de support.
Intégration avec la virtualisation, les bases de données et les charges de travail critiques
Dans un environnement virtualisé, la stratégie 3-2-1 doit distinguer les sauvegardes au niveau de la machine virtuelle et au niveau de l’application. Les snapshots hyperviseur sont utiles pour des restaurations rapides, mais ne remplacent pas des sauvegardes cohérentes au niveau des bases de données ou des applications transactionnelles. Les outils de sauvegarde modernes utilisent des agents applicatifs ou des intégrations natives avec les moteurs de bases de données pour garantir la cohérence des journaux et des transactions.
Les charges de travail critiques, comme les systèmes de facturation, les outils de gestion de production ou les applications de santé, nécessitent des objectifs RPO et RTO plus ambitieux. Dans ce cas, la première copie de sauvegarde sur disque peut être prise très fréquemment (sauvegarde incrémentale ou différentielle rapprochée), tandis que la copie hors site sur bande ou stockage objet est mise à jour selon un rythme adapté aux risques et aux contraintes de bande passante.
Prise en compte des environnements NAS, SAN et des clusters de virtualisation
Les baies SAN hébergeant les volumes de production doivent être intégrées à la politique de sauvegarde via des snapshots de baie, des réplications synchrones ou asynchrones et des flux de sauvegarde classiques. Les NAS concentrent souvent un grand nombre de fichiers utilisateurs et de partages d’équipes ; leur sauvegarde exige une gestion fine des fenêtres de sauvegarde, des droits d’accès et de la déduplication pour contenir les volumes.
Les clusters de virtualisation ajoutent une couche de complexité avec la mobilité des machines virtuelles entre hôtes. La solution de sauvegarde doit s’intégrer avec l’hyperviseur pour suivre ces déplacements et garantir que toutes les machines sont bien protégées, quel que soit l’hôte actif. Dans ce contexte, la règle 3-2-1 sert de cadre pour répartir les copies entre stockage local du site principal, site secondaire ou cloud, et éventuelle sauvegarde sur bande, tout en conservant une vision globale de la protection de l’infrastructure.
Quelles sont les limites de la stratégie 3-2-1 classique face aux menaces modernes ?
Vulnérabilités des sauvegardes en ligne et des partages réseau exposés
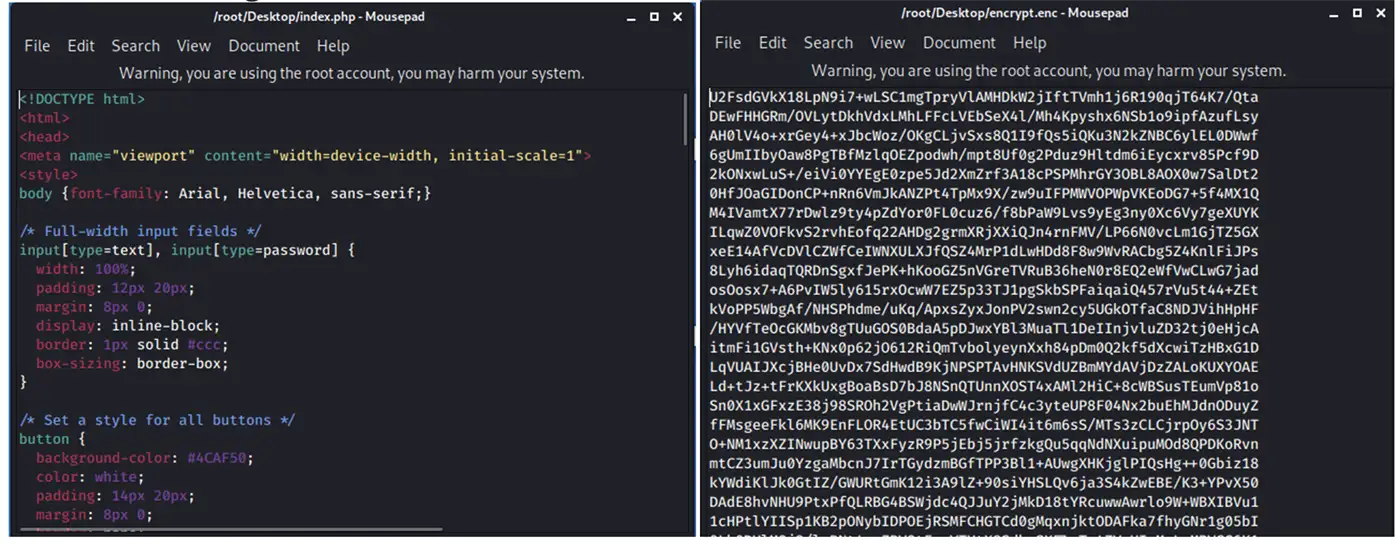
Même correctement appliquée, la stratégie de sauvegarde 3-2-1 classique suppose souvent que les sauvegardes restent accessibles en permanence depuis le réseau de production. Cette hypothèse était raisonnable lorsque les principales menaces étaient les pannes matérielles ou les erreurs humaines. Elle devient fragile dès lors que les attaquants ciblent directement les serveurs de sauvegarde, les partages réseau et les consoles d’administration. Un compte privilégié compromis suffit parfois à supprimer ou chiffrer l’ensemble des jeux de sauvegarde disponibles en ligne.
Les partages réseau utilisés comme cible de sauvegarde présentent un risque particulier lorsqu’ils sont montés en permanence sur les serveurs ou les postes clients. Un chiffreur malveillant qui parcourt les lettres de lecteurs et les chemins réseau peut ainsi atteindre à la fois les données de production et les copies de sauvegarde, annulant l’avantage de disposer de plusieurs copies.
Le petit graphique ci-dessous permet de visualiser la proportion de données réellement isolées par rapport aux copies toujours connectées au réseau, et met en évidence le déficit d’isolation dans de nombreuses implémentations 3-2-1.
Part de données véritablement isolées
Dans beaucoup d’infrastructures, seule une fraction des sauvegardes est réellement hors ligne ou immuable. Ce graphique circulaire illustre une répartition type.
Contraintes de scalabilité et explosion des volumes de données
La croissance continue des volumes de données complique également l’application naïve de la règle 3-2-1. Multiplier les copies sur des supports identiques sans optimisation conduit à des coûts de stockage et de bande passante difficilement soutenables. Les fenêtres de sauvegarde s’allongent, les restaurations complètes deviennent plus rares, et les équipes d’exploitation réduisent parfois la fréquence des sauvegardes pour préserver les ressources, ce qui dégrade les objectifs RPO.
Dans de nombreux environnements, la sauvegarde de fichiers non structurés, de machines virtuelles volumineuses et de bases de données transactionnelles exige des mécanismes complémentaires : déduplication globale, sauvegardes incrémentales permanentes, compression avancée, tiering automatique vers des classes de stockage moins coûteuses. Sans ces mécanismes, la règle 3-2-1 reste théorique et peut être contournée par des pratiques opérationnelles dégradées.
Limites des snapshots et répliques non isolés dans les scénarios d’attaque
Les snapshots de baie, de NAS ou d’hyperviseur sont très utiles pour réduire les temps de restauration, mais ils ne deviennent pas des sauvegardes à part entière tant qu’ils restent dans le même domaine d’administration et de sécurité que la production. Un ransomware ou un administrateur malveillant capable de supprimer ces snapshots efface en quelques minutes plusieurs points de reprise.
Les répliques synchrones ou asynchrones entre sites souffrent du même problème : elles propagent parfaitement la corruption ou le chiffrement malveillant vers le site secondaire. Sans isolation forte, sans immutabilité ou sans protection spécifique des métadonnées, la stratégie 3-2-1 classique ne suffit plus pour contrer les attaques modernes et doit être complétée par des copies réellement isolées, qu’elles soient copies de sauvegarde hors ligne ou immuables.
En quoi les ransomwares remettent-ils en cause les approches classiques de sauvegarde 3-2-1 ?
Vecteurs d’attaque typiques des ransomwares sur les systèmes de sauvegarde
Les groupes de ransomware visent désormais directement les infrastructures de sauvegarde pour empêcher toute restauration efficace. Après compromission d’un compte administratif ou d’un serveur, ils recensent les consoles de sauvegarde, les dépôts de données, les partages réseau et les coffres de clés. Ils tentent ensuite de désactiver les jobs planifiés, de réduire les durées de rétention ou de supprimer les jeux les plus récents. Une stratégie 3-2-1 purement théorique, sans cloisonnement ni limitation des privilèges, devient alors insuffisante, car les trois copies peuvent être affaiblies par les mêmes actions malveillantes.
Risques de chiffrement simultané des données de production et des copies en ligne
Lorsque les copies de sauvegarde restent en ligne, montées en permanence sur le réseau de l’entreprise, un chiffreur peut atteindre à la fois les volumes de production et les dépôts de sauvegarde. Le risque est encore plus élevé lorsque les mêmes identifiants sont utilisés pour administrer serveurs de fichiers, hyperviseurs et appliances de sauvegarde. Dans plusieurs incidents récents, les attaquants ont attendu plusieurs cycles complets de sauvegarde avant de déclencher l’attaque, afin que les versions saines soient écrasées. La présence de trois copies ne protège donc plus si elles partagent la même surface d’attaque.
Rôle des copies immuables et des supports hors ligne dans la prévention des altérations
La réponse consiste à introduire une véritable rupture d’accès. Les copies immuables, stockées sur du stockage objet avec verrouillage WORM ou sur des systèmes de fichiers à rétention non modifiable, empêchent la suppression ou la réécriture des données pendant une période définie. En parallèle, des supports hors ligne comme les bandes LTO retirées de la bibliothèque ou des disques déconnectés garantissent qu’une partie des sauvegardes reste totalement en dehors du périmètre de l’attaque. Une stratégie 3-2-1 moderne prévoit donc explicitement un pourcentage de jeux de sauvegarde immuables ou physiquement déconnectés.
Stratégies de restauration post-attaque et réduction de la fenêtre d’exposition
Après un incident de type ransomware, la question n’est plus seulement « dispose-t-on d’une copie ? », mais « quelle copie est restée intègre et à quel rythme peut-on la restaurer ? ». Les plans de reprise doivent identifier à l’avance les jeux immuables ou hors ligne utilisables, les systèmes restaurés en priorité et l’infrastructure de secours sur laquelle les remonter. Des tests réguliers de restauration à partir de ces sources, dans un environnement isolé, réduisent fortement la fenêtre d’exposition et permettent de valider que la stratégie 3-2-1, complétée par ces mécanismes, reste réellement opérationnelle face aux ransomwares.
Que change la variante 3-2-1-1-0 pour renforcer la résilience face aux ransomwares ?
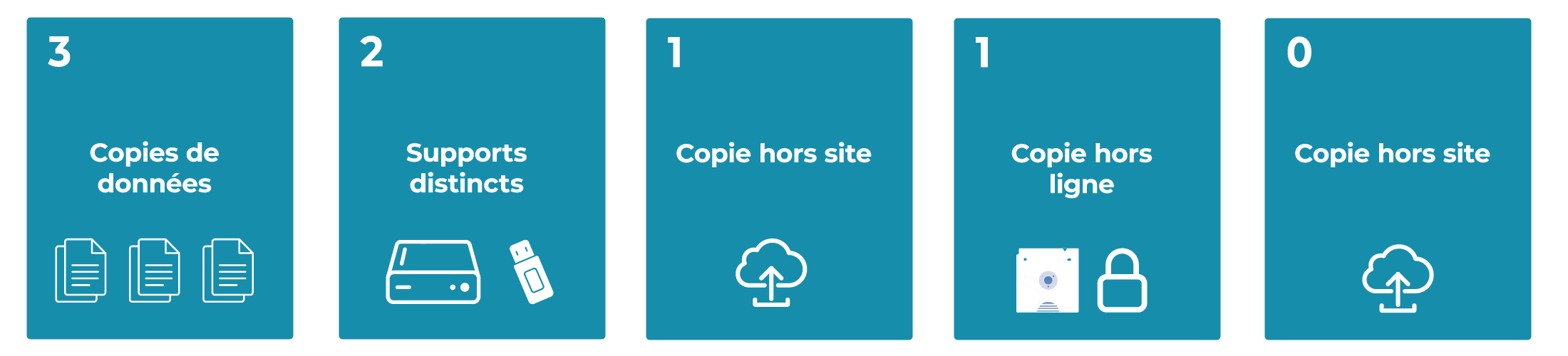
Principe de la copie hors ligne ou air-gapped
La variante 3-2-1-1-0 reprend la stratégie de sauvegarde 3-2-1 et ajoute une exigence forte : au moins une copie doit être réellement hors ligne ou fortement isolée, dite air-gapped. Cette copie n’est pas simplement stockée sur un autre site, elle est physiquement ou logiquement déconnectée de l’infrastructure de production la plupart du temps. Bandes LTO sorties de la bibliothèque, cartouches stockées dans un coffre, disques durs débranchés ou dépôt de sauvegarde n’acceptant des connexions que durant une fenêtre très courte sont des mises en œuvre typiques. L’objectif est d’empêcher un ransomware, même avec des droits élevés, d’atteindre ce jeu de sauvegarde.
Sauvegarde “0 erreur de restauration” et tests systématiques
Le “0” de 3-2-1-1-0 ne promet pas l’infaillibilité, il impose une discipline : viser zéro erreur lors des restaurations de test. Une sauvegarde qui n’a jamais été restaurée peut être corrompue, incomplète ou déjà chiffrée sans que personne ne s’en rende compte. La variante 3-2-1-1-0 demande donc de planifier des restaurations régulières, automatisées autant que possible, sur des environnements isolés. Ces exercices portent par exemple sur une machine virtuelle critique, une base de données métier ou un partage de fichiers volumineux, et leurs résultats sont suivis comme des indicateurs à part entière du plan de reprise après sinistre.
Rôle des médias WORM, des bandes LTO et du stockage objet immuable
Pour rendre l’attaque plus difficile encore, la stratégie 3-2-1-1-0 exploite des médias WORM et du stockage objet immuable. Les supports WORM, physiques ou logiques, empêchent toute modification ou suppression avant la fin d’une période de rétention définie. Les bandes LTO sont particulièrement adaptées à ce rôle, car elles combinent faible coût par téraoctet, stockage hors ligne et bonne durée de vie. Le stockage objet immuable, déployé sur site ou dans le cloud, permet de verrouiller les objets de sauvegarde pour une durée déterminée, même vis-à-vis d’un administrateur disposant de droits étendus, ce qui limite fortement l’impact d’un compte compromis.
Cas d’usage typiques dans les environnements sensibles
Les secteurs de la santé, de la finance, de l’industrie critique et du secteur public adoptent en priorité 3-2-1-1-0, car la perte ou l’indisponibilité prolongée de leurs données est inacceptable. Dans ces organisations, la stratégie est souvent formalisée dans une politique qui décrit, pour chaque système critique, les supports utilisés, les niveaux d’isolement et d’immutabilité, la localisation des copies et la fréquence des tests de restauration. Cette formalisation facilite les audits et permet de démontrer que la protection anti-ransomware repose sur des mécanismes concrets, mesurables et régulièrement contrôlés, et non sur des principes généraux difficiles à vérifier.
Quelles variantes modernes étendent la règle 3-2-1 dans les environnements hybrides et cloud ?
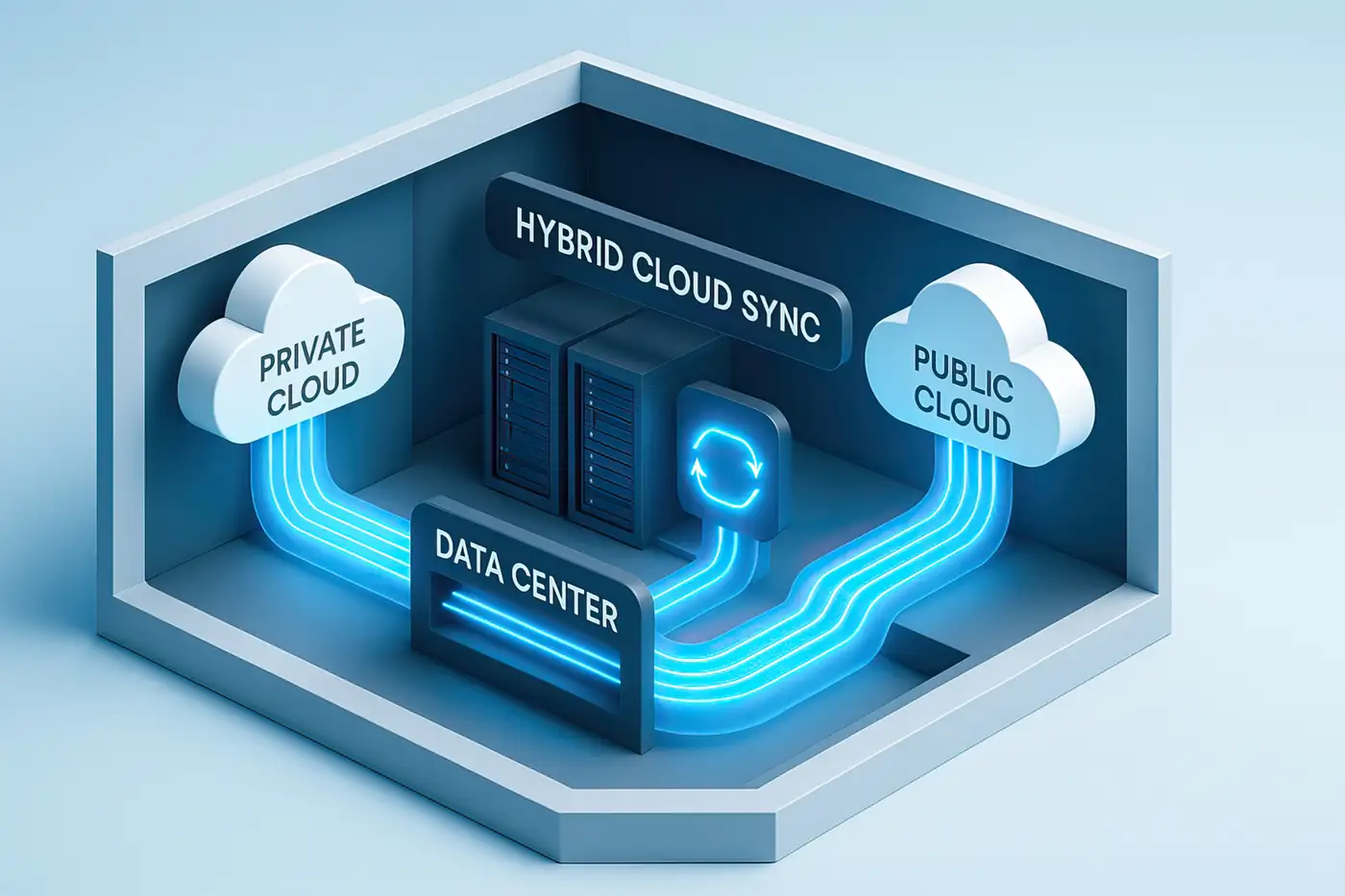
Adaptation de la règle 3-2-1 aux environnements hybrides et multicloud
Dans les environnements hybrides, où les données sont réparties entre centres de données internes et services cloud publics, la stratégie de sauvegarde 3-2-1 doit être adaptée sans en dénaturer les principes. Les copies locales restent indispensables pour les restaurations rapides, mais une partie des sauvegardes peut être déportée vers le cloud pour bénéficier de la résilience et de la redondance du fournisseur. La difficulté consiste à garantir que ces copies restent réellement indépendantes des mécanismes de haute disponibilité et de réplication déjà en place.
En pratique, cela impose de distinguer clairement réplication, haute disponibilité et sauvegarde. La réplication entre sites ou zones de disponibilité sert à maintenir un service en ligne, alors que la sauvegarde vise à reconstituer un état antérieur. Une règle 3-2-1 appliquée au cloud exige que les sauvegardes disposent de cycles de rétention propres, d’un espace logique dédié et de contrôles d’accès distincts de ceux utilisés pour l’administration courante.
Introduction et cas d’usage de la variante 4-3-2 avec redondance accrue
La variante 4-3-2 étend le modèle en ajoutant une copie supplémentaire et un support ou emplacement additionnel. L’objectif est de couvrir des scénarios où deux sites physiques ou deux fournisseurs de cloud pourraient être impactés simultanément, par exemple en cas de panne logicielle globale ou de configuration erronée répliquée. On peut ainsi combiner une copie locale sur disque, une copie sur bande, une copie dans un cloud principal et une autre dans un second fournisseur ou une autre région géographique.
Le tableau ci-dessous illustre la répartition possible des copies dans une architecture combinant 3-2-1-1-0 et 4-3-2 pour différents niveaux de criticité.
Exemple de répartition des copies par niveau de criticité
Le graphique compare le nombre de copies et d’emplacements utilisés pour trois familles de systèmes : critiques, importants et standard.
Combinaison des variantes dans une architecture globale de sauvegarde
En pratique, une même organisation n’applique pas une unique variante à l’ensemble de son système d’information. Les applications les plus critiques peuvent bénéficier d’une stratégie proche de 4-3-2 et 3-2-1-1-0 combinées, tandis que des services moins sensibles restent sur un schéma 3-2-1 classique, complété par une seule copie immuable dans le cloud. L’essentiel est de documenter pour chaque périmètre métier le nombre de copies, les supports utilisés, les sites impliqués et les niveaux d’isolement.
Gestion des topologies multi-sites et des contraintes de latence réseau
Les environnements multi-sites et multicloud imposent enfin de prendre en compte la latence réseau et les débits réellement disponibles. Une politique qui impose de copier systématiquement tous les jeux de sauvegarde vers un second fournisseur peut devenir impraticable en termes de temps de transfert et de coûts. Il est souvent plus pertinent de réserver les copies les plus redondantes aux données véritablement critiques, en combinant bande hors site, stockage objet immuable et répliques dans plusieurs régions cloud.
Comment implémenter une stratégie 3-2-1 moderne dans le cloud et les environnements hybrides ?
Sélection de fournisseurs cloud et redondance géographique des données de sauvegarde
Dans un contexte hybride, le choix des fournisseurs cloud ne se résume pas à une comparaison de prix au gigaoctet. Il faut analyser la façon dont chaque fournisseur gère la redondance interne, les zones de disponibilité, les classes de stockage et la sortie de données. Dans une stratégie 3-2-1 moderne, le cloud est souvent utilisé comme emplacement hors site principal ou secondaire, avec des données répliquées sur plusieurs zones au sein d’une même région ou entre régions distinctes.
En pratique, il est utile de définir des profils de données : systèmes critiques, applications importantes, services standard. Pour chaque profil, on associe un niveau de redondance géographique et un type de stockage. Les données les plus sensibles peuvent bénéficier d’une réplication inter-régions, tandis que les données moins critiques restent dans une seule région avec des sauvegardes ponctuelles exportées vers un second emplacement. L’objectif est de garantir qu’une défaillance régionale ou un incident de sécurité localisé n’entraîne pas la perte de toutes les copies.
Configuration de sauvegardes automatisées, chiffrées et segmentées par criticité
La plupart des plateformes cloud proposent des mécanismes natifs de sauvegarde pour les machines virtuelles, les bases de données managées et les services de fichiers. Ces mécanismes doivent être orchestrés au sein d’une politique 3-2-1 globale, et non laissés à la configuration par défaut de chaque équipe projet. Les sauvegardes doivent être planifiées, chiffrées systématiquement et réparties dans des coffres ou des comptes dédiés, afin d’éviter qu’un même jeu d’identifiants compromette à la fois la production et les copies.
Segmenter les sauvegardes par niveau de criticité est essentiel. Les systèmes critiques bénéficieront de sauvegardes plus fréquentes, de rétentions plus longues et d’une duplication vers un second fournisseur ou un site sur site. Les environnements de test ou les services non essentiels peuvent utiliser des politiques plus simples, avec des rétentions plus courtes. Ce découpage évite de surdimensionner la stratégie pour des systèmes peu sensibles tout en garantissant un niveau de protection élevé pour les applications métier centrales.
Utilisation de coffres-forts de clés, de rôles et de politiques IAM pour sécuriser les sauvegardes
Dans le cloud, la sécurité des sauvegardes dépend directement de la gestion des identités et des clés de chiffrement. Les clés doivent être gérées dans des coffres-forts dédiés, avec rotation régulière, journalisation des accès et séparation nette des rôles entre équipes de production, équipes de sauvegarde et administrateurs de la sécurité. Une bonne pratique consiste à limiter strictement le nombre de comptes capables de supprimer des sauvegardes ou de modifier des politiques de rétention.
Les rôles IAM doivent refléter cette séparation des responsabilités : un compte chargé d’exploiter les machines virtuelles ou les bases de données ne devrait pas pouvoir altérer les sauvegardes ou désactiver l’immutabilité. Dans certains scénarios, il est pertinent de placer les sauvegardes dans un compte ou un abonnement séparé, avec une liaison réseau contrôlée et des droits minimaux, ce qui rapproche la stratégie cloud d’un modèle de séparation logique proche de l’air-gapping.
Monitoring, alertes et tests de récupération réguliers dans les environnements cloud
Une stratégie 3-2-1 moderne dans le cloud ne peut pas se limiter à lancer des sauvegardes. Il faut vérifier en permanence que les jobs se déroulent correctement, que les volumes attendus sont bien copiés et que les fenêtres d’exécution restent compatibles avec les engagements opérationnels. Les tableaux de bord de sauvegarde doivent suivre les taux de succès, les volumes sauvegardés, les temps de restauration observés et les éventuelles dérives de configuration.
Les tests de récupération dans le cloud peuvent être automatisés en reconstruisant régulièrement un ensemble de machines ou de services dans un environnement isolé, puis en validant leur bon fonctionnement applicatif. Ces exercices servent à détecter les erreurs de configuration, les problèmes de dépendances et les écarts entre ce qui est documenté et ce qui est réellement restaurable. Intégrés dans une démarche de revue régulière des risques, ils permettent d’ajuster la stratégie 3-2-1, d’affiner les durées de rétention et de s’assurer que les sauvegardes restent exploitables malgré l’évolution des architectures et des services consommés.
Comment intégrer le stockage immutable et le stockage objet dans une stratégie 3-2-1-1-0 ?

Apport du stockage objet avec verrouillage WORM et immutabilité des sauvegardes
Le stockage objet joue un rôle central dans les stratégies de sauvegarde modernes, en particulier lorsqu’il supporte des fonctions d’immutabilité et de verrouillage WORM. Contrairement à un volume bloc ou à un partage fichier classique, un dépôt objet permet de définir des politiques de rétention à l’échelle de seaux ou de préfixes, empêchant toute suppression ou modification des objets pendant une durée déterminée. Cette capacité répond directement à la variante 3-2-1-1-0, qui impose au moins une copie réellement protégée contre les altérations, même en cas de compromission de comptes administratifs.
Dans une architecture 3-2-1-1-0, le stockage objet immuable est souvent utilisé comme destination de la copie hors site ou comme quatrième copie dans une approche de type 4-3-2. Les jeux de sauvegarde y sont transférés après déduplication et chiffrement, puis verrouillés pour une durée ajustée aux exigences métiers et réglementaires. La combinaison chiffrement + immutabilité réduit fortement la surface d’attaque : un ransomware ne peut pas réécrire les objets, et un administrateur ne peut pas les supprimer avant la fin de la période de rétention sans passer par des procédures exceptionnelles contrôlées.
Combinaison bande LTO, disque, NAS/SAN et cloud pour une architecture hybride
Une stratégie 3-2-1-1-0 efficace ne repose pas sur un seul type de support, mais sur une combinaison contrôlée de technologies. Le disque (appliance de sauvegarde ou NAS) fournit la première ligne pour des restaurations rapides sur site. La bande LTO assure une rétention longue durée hors ligne, particulièrement adaptée aux données d’archivage et aux besoins de protection contre les ransomwares. Le stockage objet, sur site ou dans le cloud, apporte l’immutabilité et la scalabilité pour les volumes importants.
L’objectif n’est pas de multiplier les supports de manière désordonnée, mais de leur attribuer un rôle clair : disque pour la restauration rapide, bande pour l’isolement physique, objet immuable pour l’isolement logique et la montée en capacité. Le tableau ci-dessous illustre une répartition typique des rôles dans une architecture hybride.
| Niveau | Support principal | Usage typique | Rétention cible |
|---|---|---|---|
| Niveau 1 | Disque (appliance, NAS) | Restauration rapide après incident courant | Quelques jours à quelques semaines |
| Niveau 2 | Bande LTO hors ligne | Protection anti-ransomware, archivage longue durée | Plusieurs années selon contraintes métiers |
| Niveau 3 | Stockage objet immuable (on-premise ou cloud) | Sauvegardes critiques, copie hors site 3-2-1-1-0 | De quelques mois à plusieurs années |
Gestion des niveaux de stockage pour optimiser coût, performance et rétention
La mise en place de plusieurs niveaux de stockage permet de concilier budget, performance et exigences de conformité. Les sauvegardes récentes et les systèmes les plus critiques sont conservés sur disque performant pour limiter les temps de restauration. Au fil du temps, les jeux les plus anciens sont automatiquement déplacés vers des classes de stockage objet à coût réduit ou vers la bande, selon les politiques de cycle de vie définies dans l’outil de sauvegarde ou directement dans la plateforme de stockage objet.
Cette approche hiérarchisée évite de conserver indéfiniment sur disque des volumes qui n’ont plus besoin d’un accès rapide, tout en respectant les durées de rétention imposées par les métiers ou la réglementation. Le plan 3-2-1-1-0 sert de grille de lecture : à chaque niveau de stockage correspond un rôle dans la stratégie globale, avec un niveau d’isolement, un coût moyen par téraoctet et un profil de performance.
Latence de restauration et fenêtres de maintenance dans les architectures 3-2-1-1-0
L’intégration du stockage immuable et de la bande dans une stratégie 3-2-1-1-0 introduit une contrainte supplémentaire : la latence de restauration. Restaurer depuis une bande hors site ou depuis un stockage objet situé dans une autre région prend plus de temps que depuis un disque local. Il est donc indispensable de distinguer les scénarios de restauration rapide (incident technique isolé) des scénarios de reprise après sinistre majeur, où l’on accepte des délais plus longs.
Les fenêtres de maintenance doivent intégrer ces durées de restauration potentielles. Lorsqu’un test de reprise à partir d’une copie immuable ou d’une bande est planifié, il doit disposer d’un créneau suffisant pour couvrir la récupération des données, leur validation et la remise en service des applications. En pratique, cela conduit souvent à définir des procédures distinctes pour la restauration “quotidienne” depuis le disque et pour la restauration “de dernier recours” depuis les niveaux immuables ou hors ligne, tout en conservant une vue d’ensemble cohérente au niveau de la stratégie 3-2-1-1-0.
Comment adapter la stratégie 3-2-1 aux contraintes réglementaires et aux audits de conformité ?
Alignement avec les obligations de rétention des données et les normes sectorielles
L’adaptation de la stratégie de sauvegarde 3-2-1 aux contraintes réglementaires commence par un inventaire précis des obligations de rétention applicables à chaque famille de données. Données financières, dossiers de santé, informations clients, données de traçabilité industrielle ou documents contractuels n’ont pas les mêmes durées de conservation ni les mêmes règles de destruction. La politique de sauvegarde doit donc traduire ces exigences en durées de rétention, emplacements autorisés et modalités de purge contrôlée.
Les référentiels de sécurité et de continuité d’activité, tels qu’ISO 27001 ou ISO 22301, insistent sur la capacité à restaurer l’information dans les délais définis par les objectifs de continuité. La stratégie 3-2-1 sert de socle technique pour démontrer qu’il existe plusieurs copies indépendantes, réparties sur des supports et des sites distincts, avec des rétentions cohérentes avec les textes applicables. Cette cohérence doit être documentée explicitement, par exemple dans un registre des traitements ou un schéma directeur de sauvegarde et d’archivage.
| Type de données | Durée de rétention cible | Support principal de sauvegarde | Remarque conformité |
|---|---|---|---|
| Comptabilité / finance | 6 à 10 ans | Disque + bande LTO | Conservation légale, audits récurrents |
| Données de santé | Selon réglementation locale | Stockage objet immuable + bande | Exigences fortes de confidentialité |
| Données de logs / traçabilité | De quelques mois à plusieurs années | Disque + cloud objet | Support d’enquêtes internes et externes |
Chiffrement, localisation des données et souveraineté numérique
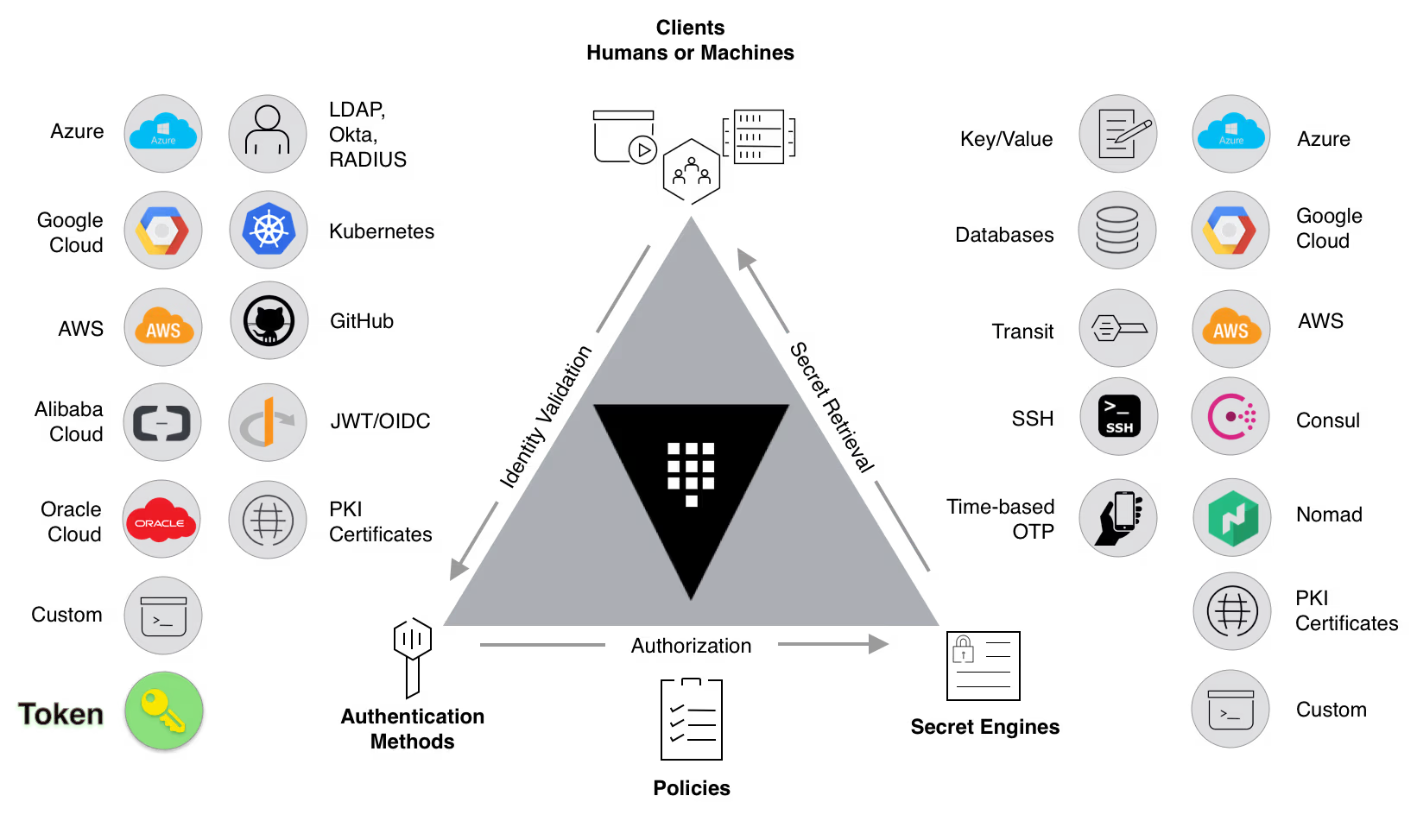
Une stratégie 3-2-1 moderne doit également intégrer les contraintes de localisation et de souveraineté des données. Lorsqu’une copie hors site est stockée dans le cloud ou dans un autre pays, il est nécessaire de vérifier la compatibilité avec les réglementations en vigueur : transfert de données personnelles, lois extraterritoriales, exigences contractuelles des clients. Le chiffrement systématique des sauvegardes, avec des clés maîtrisées par l’organisation, devient un prérequis pour limiter l’exposition en cas d’accès non autorisé au stockage.
La localisation des coffres de clés, la gestion des rôles d’administration et la séparation des responsabilités entre hébergeur et client doivent être formalisées. Une politique de sauvegarde 3-2-1 adaptée aux enjeux de souveraineté précise, pour chaque copie, dans quel pays ou région elle est stockée, qui administre les supports, qui contrôle les clés de chiffrement et selon quel processus les données peuvent être restaurées ou détruites. Cette granularité est indispensable pour répondre de manière factuelle aux questions des auditeurs et des autorités de contrôle.
Traçabilité, journaux et rapports de sauvegarde pour les audits
Les audits internes et externes ne se contentent plus d’un schéma théorique de sauvegarde. Ils exigent des preuves : journaux d’exécution, rapports d’erreurs, détails des restaurations de test, inventaires des supports et des jeux de sauvegarde conservés. La mise en œuvre de 3-2-1 doit donc s’accompagner d’une collecte systématique des traces d’exécution et de tableaux de bord permettant de démontrer la réalité des sauvegardes, leur fréquence, les durées de rétention effectives et le niveau de succès des tâches planifiées.
Dans les environnements matures, ces informations sont intégrées à un outil de supervision ou à une plateforme de gestion des événements de sécurité, afin de corréler les incidents de sauvegarde avec les événements de sécurité et les changements d’infrastructure. Cette corrélation permet d’identifier des zones de risque, par exemple un périmètre nouvellement déployé où la stratégie 3-2-1 n’a pas encore été appliquée correctement.
Intégration de la gouvernance des données dans la politique de sauvegarde et d’archivage
Adapter 3-2-1 aux contraintes réglementaires impose enfin de lier la politique de sauvegarde à la gouvernance globale des données. Les référentiels de données, les cartographies d’applications et les registres de traitements doivent indiquer, pour chaque catégorie d’information, comment elle est sauvegardée, pendant combien de temps et sur quels supports. Cette intégration permet d’éviter les incohérences classiques, comme des données censées être anonymisées ou purgées mais toujours présentes dans de vieilles sauvegardes non maîtrisées.
La gouvernance des données doit également couvrir les processus de restauration : quelles données peuvent être restaurées, sur quel périmètre, à la demande de qui et avec quel niveau de validation. Dans certains secteurs, restaurer des données anciennes alors qu’elles auraient dû être supprimées peut constituer un non-respect des règles de protection des données. Une stratégie 3-2-1 réellement conforme ne se limite donc pas à la technologie de sauvegarde, elle s’inscrit dans un cadre global où les métiers, la sécurité, le juridique et l’IT partagent une vision commune des cycles de vie de l’information.
Quels indicateurs et tests de restauration suivre pour valider l’efficacité d’une stratégie 3-2-1 moderne ?
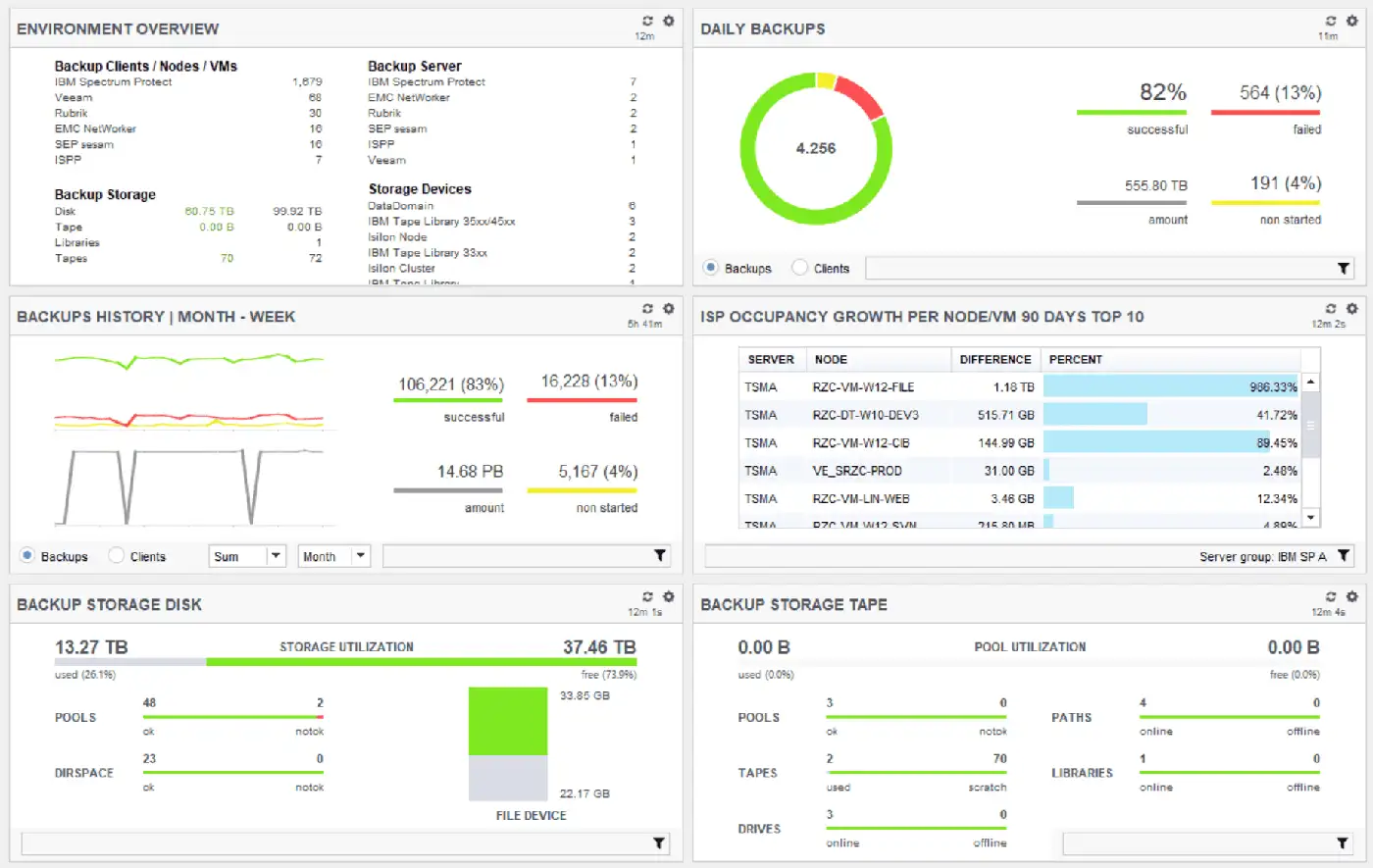
Fréquence et méthodologie des tests de restauration partielle et complète
Une stratégie de sauvegarde 3-2-1, même bien conçue, reste théorique tant que les restaurations ne sont pas testées régulièrement. Les tests de restauration partielle consistent à récupérer un fichier, une base de données isolée ou une machine virtuelle, puis à vérifier l’intégrité fonctionnelle et la cohérence des données. Ils doivent être planifiés à une fréquence élevée, par exemple mensuelle, sur un échantillon représentatif des systèmes critiques et des données structurées et non structurées.
Les tests de restauration complète visent à reconstruire un service ou une chaîne applicative entière dans un environnement isolé : serveur d’application, base de données, composants de sécurité, intégrations. Leur fréquence est généralement plus faible (trimestrielle ou semestrielle), car ils mobilisent davantage de ressources humaines et techniques. L’objectif n’est pas uniquement de vérifier que les données sont présentes, mais de s’assurer que les procédures documentées permettent de remettre le service en ligne dans les délais prévus par le plan de reprise après sinistre.
Mesure des RPO et RTO dans différents scénarios d’incidents majeurs
Les indicateurs clés d’une stratégie 3-2-1 moderne restent les objectifs de point de reprise (RPO) et de temps de reprise (RTO). Le RPO mesure l’ancienneté maximale acceptable des données restaurées, le RTO la durée maximale d’indisponibilité tolérée pour un service. Lors des exercices de restauration, il est indispensable de mesurer les RPO et RTO réellement atteints, et pas seulement ceux définis sur le papier. Ces mesures doivent couvrir plusieurs scénarios : panne d’un serveur isolé, indisponibilité d’une baie de stockage, perte d’un site complet, contamination par ransomware.
En comparant les RPO et RTO observés aux objectifs cibles, l’organisation identifie les écarts à corriger : fréquence de sauvegarde insuffisante pour certaines bases de données, liens réseau saturés lors des restaurations à partir du cloud, procédures manuelles trop complexes pour être exécutées dans les délais. Ces écarts peuvent conduire à revoir la répartition des copies entre supports, à privilégier des sauvegardes incrémentales plus fréquentes ou à renforcer l’automatisation des étapes de reprise.
| Indicateur | Description | Valeur cible | Périmètre typique |
|---|---|---|---|
| RPO | Ancienneté maximale des données restaurées | 15 min à 4 h selon criticité | Bases de données métiers |
| RTO | Temps maximal d’indisponibilité du service | 1 h à 24 h | Applications critiques et support |
| Taux de succès des sauvegardes | Proportion de jobs terminés sans erreur | > 98 % sur période glissante | Ensemble des périmètres protégés |
| Temps moyen de restauration | Durée moyenne entre lancement et fin de restauration | Adapté aux engagements métiers | Fichiers, VM, bases de données |
Suivi du taux de succès des sauvegardes et des temps moyens de restauration
Le taux de succès des sauvegardes est un indicateur simple mais critique. Un pourcentage élevé d’échecs répétés sur un même périmètre signale soit un problème de capacité (stockage saturé, bande passante insuffisante), soit un défaut de configuration (fenêtre de sauvegarde mal adaptée, droits insuffisants). Les temps moyens de restauration, mesurés lors de tests et d’incidents réels, permettent de vérifier que les processus restent réalistes malgré la croissance des volumes et l’évolution des systèmes.
Ces indicateurs doivent être suivis dans le temps, avec des seuils d’alerte clairs. Une dérive progressive des temps de restauration peut par exemple signaler que les jeux de sauvegarde deviennent trop volumineux et qu’il faut revoir la stratégie : déduplication plus agressive, filtrage des données inutiles, ajustement des fréquences. De la même façon, une hausse des échecs sur une catégorie de serveurs peut révéler un changement récent (mise à jour logicielle, migration vers une nouvelle plateforme) qui nécessite une adaptation des paramètres de sauvegarde.
Pilotage via tableaux de bord, revues de risques et amélioration continue
Pour que la stratégie 3-2-1 reste efficace, les indicateurs de sauvegarde doivent être intégrés dans les tableaux de bord de la direction des systèmes d’information et des équipes de production. Les principaux KPI (RPO, RTO, taux de succès, volumes sauvegardés, saturation des supports, temps de restauration) doivent être consolidés et commentés régulièrement lors de revues de risques. Ces revues permettent de prioriser les actions : ajouter une copie immuable pour certains systèmes, renforcer la capacité de stockage, optimiser les fenêtres de sauvegarde ou ajuster les durées de rétention.
La stratégie 3-2-1 moderne est donc un processus d’amélioration continue, pas un projet ponctuel. Chaque incident, chaque test de restauration et chaque audit fournit des informations qui doivent être réinjectées dans la conception de la politique de sauvegarde. En documentant ces ajustements et en maintenant une traçabilité des décisions, l’organisation démontre que sa protection des données n’est pas figée, mais évolue en fonction des menaces, des contraintes réglementaires et des besoins métiers.
Conclusion : vers une stratégie 3-2-1 réellement opérationnelle
La stratégie de sauvegarde 3-2-1 reste un socle robuste pour protéger les données d’entreprise, à condition d’être appliquée de manière rigoureuse et adaptée aux menaces actuelles. Trois copies, deux types de supports et au moins une copie hors site ne suffisent plus si toutes les copies restent accessibles en permanence depuis le même périmètre technique. Les attaques par ransomware, la croissance des volumes et la complexité des environnements hybrides imposent de compléter ce socle par une isolation réelle des sauvegardes et par des mécanismes d’immutabilité.
Les variantes modernes telles que 3-2-1-1-0 et 4-3-2 apportent précisément ce supplément de résilience : copie hors ligne ou fortement isolée, stockage objet immuable, combinaison contrôlée de disque, bande LTO et cloud, segmentation des politiques par criticité, intégration avec la virtualisation et les services managés. Elles permettent d’articuler protection contre les ransomwares, exigences de PRA, contraintes réglementaires et maîtrise des coûts, tout en restant compréhensibles pour les équipes techniques, les métiers et les auditeurs.
Une stratégie 3-2-1 moderne n’est pas figée dans une documentation ; elle se mesure et se teste en continu. Définir des indicateurs clairs (RPO, RTO, taux de succès des sauvegardes, temps de restauration), planifier des restaurations de test et ajuster régulièrement les politiques en fonction des retours d’expérience sont des éléments aussi importants que le choix des supports. C’est cette combinaison de principes simples, de technologies adaptées et de pilotage régulier qui permet à une organisation de disposer, le jour où un incident majeur survient, de sauvegardes réellement exploitables et d’un plan de reprise crédible.